在 V8 中,当某些脚本经常使用时,V8 会把这些脚本生产的代码缓存起来。从 Chrome 66 开始,当引擎在顶层执行后,我们会把生成的更多代码缓存起来。这会导致初始加载时分析和编译时间缩短 20-40%。
背景 #
V8 使用两种代码缓存策略来缓存生成的代码,以便以后重用。首先是存在于每个 V8 实例中的内存缓存(in-memory cache)。初始编译后生成的代码存储在此缓存中,以源字符串作为 key。这可以在 V8 的相同实例中重复使用。另一种代码缓存序列化生成的代码并将其存储在磁盘上供将来使用。该缓存并不只属于 V8 的特定实例,可以在 V8 的不同实例中使用。这篇博文主要关注 Chrome 中使用的第二种代码缓存。(其他嵌入程序也使用这种代码缓存;它不仅限于 Chrome,但本博文仅关注 Chrome 中的使用情况。)
Chrome 将序列化的生成代码(generated code)存储到磁盘缓存中,并使用脚本资源的 URL 作为 key。加载脚本时,Chrome 会检查磁盘缓存。如果脚本已被缓存,则 Chrome 会将序列化的数据作为编译请求的一部分传递给 V8。然后 V8 反序列化这些数据,而不是解析和编译脚本。还有额外的检查来确保代码仍然可用(例如:版本不匹配导致缓存的数据无法使用)。
真实世界的数据显示,代码缓存命中率(对于可以缓存的脚本)很高(~86%)。虽然这些脚本的缓存命中率很高,但是我们每个脚本缓存的代码量并不是很高。我们的分析表明,增加缓存的代码量可以使 JavaScript 代码的解析和编译减少大约 40% 的时间。
增加缓存的代码量 #
在以前的方法中,代码缓存与脚本的编译请求相结合。
嵌入者可以请求 V8 序列化它在顶级编译新的 JavaScript 源文件时生成的代码。编译脚本后,V8 返回序列化代码。当 Chrome 再次请求相同的脚本时,V8 会从缓存中获取序列化的代码并对其进行反序列化。V8 完全避免了重新编译已经在缓存中的函数。下图显示了这些场景: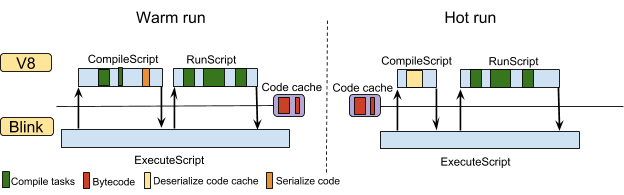
V8 仅编译在顶层编译期间的立即执行的函数(IIFE),并标记用于延迟编译的其他函数。这样可以避免编译不需要的函数,从而提高页面加载时间,但这也意味着序列化数据仅包含需要迫切编译的函数的代码。
在 Chrome 59 之前,我们必须在代码开始执行之前生成代码缓存。较早的 V8 基本编译器(Full-codegen)为执行上下文生成专用代码。Full-codegen 将代码补丁用于特定执行上下文的快速路径(fast-path)操作。当在其他执行上下文中使用的,需要删除特定于某个上下文的数据,此类代码不能被轻易地序列化。
随着在 Chrome 59 中启用 Ignition,这一限制不再是必要的。Ignition 使用数据驱动的内嵌缓存来执行当前执行上下文中的快速路径操作。上下文相关数据存储在反馈向量(feedback vector)中并与生成的代码分开。通过这种方式也就使得“执行脚本之后也能生成代码缓存”称为可能。在我们执行脚本时,会编译更多的函数(标记为惰性编译的函数),从而允许我们缓存更多的代码。
V8 公开了一个新 API,ScriptCompiler::CreateCodeCache,可以让代码缓存请求不再依赖于编译请求。在编译请求的过程中请求代码缓存已被弃用,并且不适用于 V8 v6.6 及更高版本。从版本 66 开始,Chrome 使用此 API 在顶层执行后请求代码缓存。下图显示了请求代码缓存的新场景。代码缓存在顶层执行之后被请求,并因此包含在脚本执行期间稍后被编译的函数的代码。在后面的运行中(在下图中显示为热运行),它避免了在顶层执行期间编译函数。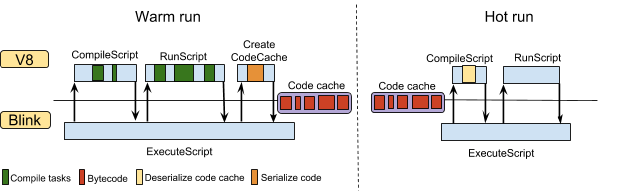
结果 #
使用我们内部的 real-world benchmarks 测试此功能的性能。下图显示了早期高速缓存方案中分析和编译时间的缩短。在大多数页面上,解析和编译时间都会减少 20-40% 左右。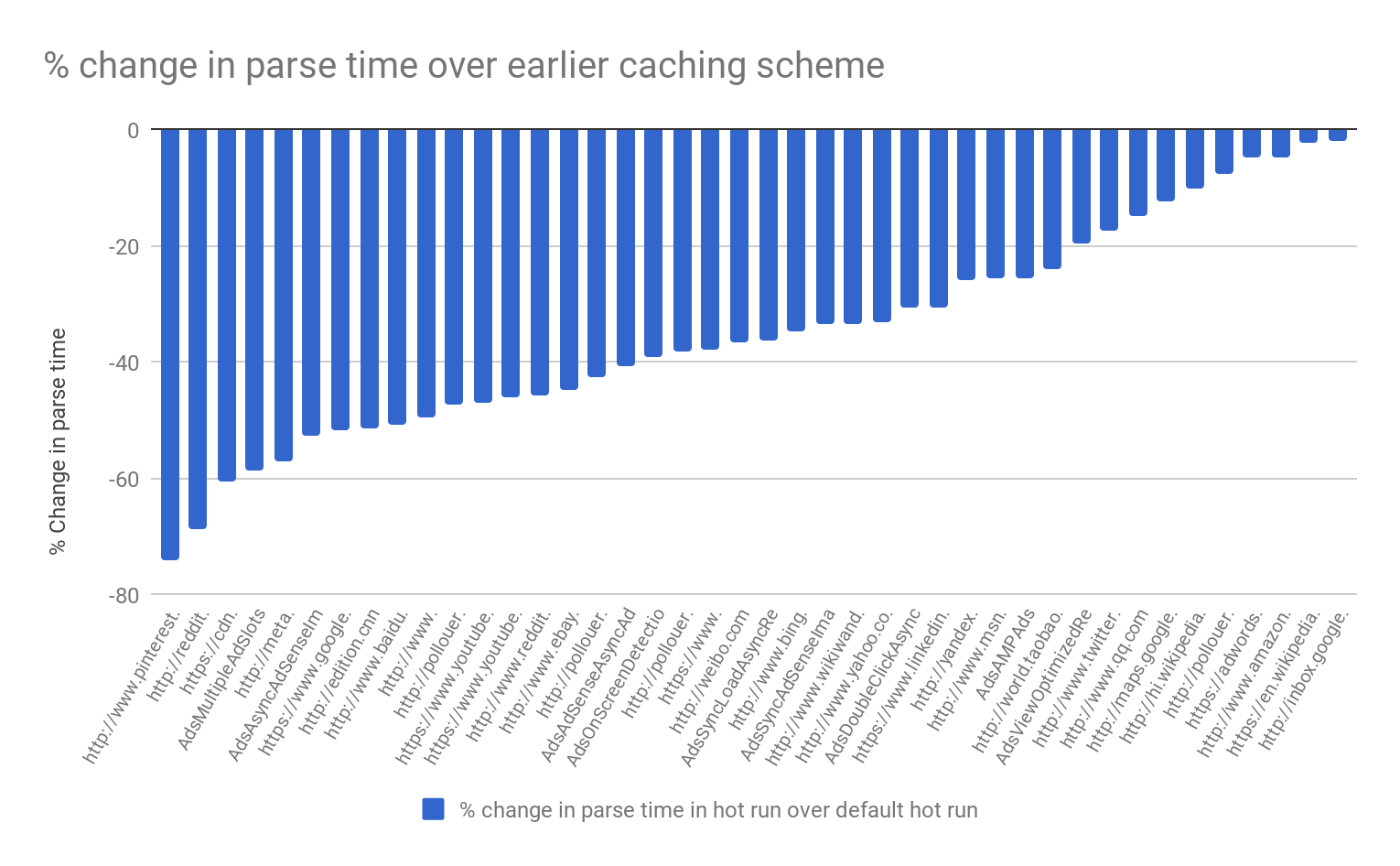
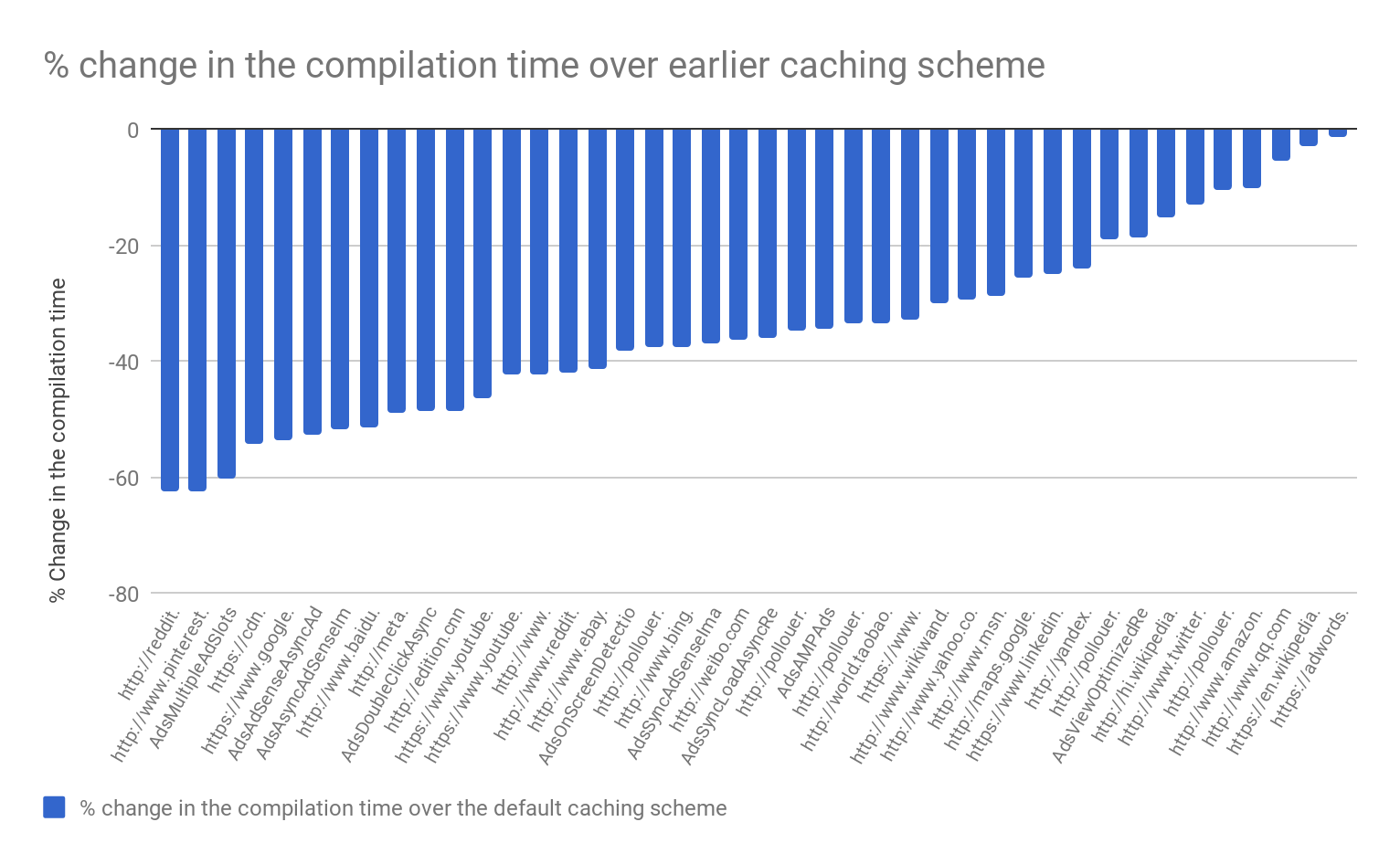
来自其它数据也显示了和我们相似的结果,在桌面和移动设备上编译 JavaScript 代码的时间减少了 20-40%。在 Android 上,这种优化还可以转化为顶级页面加载指标减少 1-2%,例如网页可以被用户操作时所需的时间。我们还监测了 Chrome 的内存和磁盘使用情况,但没有看到任何明显的回归。