上周,我们宣布针对某些类型的 JavaScript 启用了 TurboFan。在这篇文章中,我们想更深入地研究 TurboFan 的设计。
性能一直是 V8 战略的核心。与传统的 CrankShaft JIT 相比,TurboFan 将尖端的中间表示与多层转换和优化管道相结合,以生成质量更高的机器代码。与 CrankShaft 中相比,TurboFan 中的优化更多,更复杂,更彻底地得到应用,从而实现了流体代码运动(fluid code motion),控制流优化和精确的数值范围分析,而这些都是以前无法实现的。
分层架构 #
随着支持新的语言功能,添加新的优化并针对新的计算机体系结构,编译器会随着时间的流逝而变得复杂。借助 TurboFan,我们吸取了许多编译器的经验教训,并开发了分层体系结构,以使编译器能够随着时间的推移满足这些需求。源代码级语言(JavaScript),VM 的功能(V8)和体系结构的复杂性(从 x86 到 ARM 再到 MIPS)之间更清晰的区分允许代码更简洁,更健壮。分层使从事编译器工作的人员能够在实现优化和功能以及编写更有效的单元测试时在本地进行推理。它还可以保存代码。TurboFan 支持的 7 种目标体系结构中的每一种都需要少于 3,000 行平台特定代码,而 CrankShaft 中则为 13,000-16,000。这使 ARM,英特尔,MIPS 和 IBM 的工程师能够以更有效的方式为 TurboFan 做出贡献。TurboFan 能够更轻松地支持 ES6 的所有新功能,因为它的灵活设计将 JavaScript 前端与依赖于体系结构的后端分开了。
更复杂的优化 #
与 CrankShaft 相比,TurboFan JIT 通过许多高级技术实现了更积极的优化。JavaScript 以最不优化的形式进入编译器管道,并经过翻译和优化以逐步降低形式,直到生成机器代码为止。设计的核心是代码的更加宽松的 sea-of-nodes 内部表示(IR),从而可以更有效地重新排序和优化。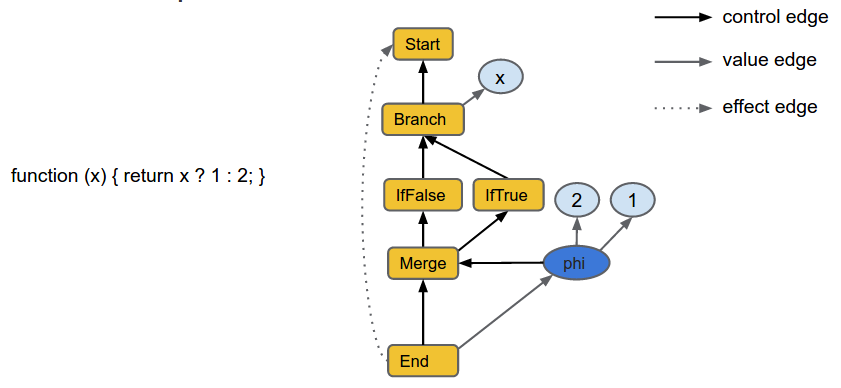 TurboFan 图示例
TurboFan 图示例
数值范围分析可帮助 TurboFan 更好地理解数字运算代码。基于图的 IR 可以将大多数优化表示为简单的局部优化(local reductions),从而更易于独立编写和测试。优化引擎以系统和彻底的方式应用这些本地规则。从图形表示中过渡涉及一种创新的调度算法,该算法利用重新排序的自由度将代码移出循环并移入执行频率较低的路径。最后,特定于体系结构的优化(例如复杂的指令选择)会利用每个目标平台的功能来获得最佳质量的代码。
我们已经看到 TurboFan 可以大大提高速度,但是仍有大量工作要做。请继续关注我们的更多优化,并为更多类型的代码应用 TurboFan!