注:如果您更喜欢观看演示文稿,请欣赏下面的视频!如果没有,请跳过视频并继续阅读。
过去几年中,JavaScript 性能的大幅改进很大程度上依赖于浏览器解析和编译 JavaScript 的速度。在 2019 年,处理 JavaScript 的主要性能损耗在于下载和 CPU 执行时间。
浏览器主线程忙于执行 JavaScript 时,用户交互会被延迟,因此脚本执行时间和网络上的瓶颈优化尤其重要。
可行的高级指南 #
这对于 web 开发者意味着什么?解析和编译的性能损耗不再像从前我们认为的那样慢。我们需要关注三点:
- 提升下载速度
- 减小 JavaScript 包的体积,尤其是在移动设备上。更小的包可以提升下载速度,带来更低的内存占用,并减少 CPU 性能损耗。
- 避免把代码打包成一个大文件。如果一个包超过 50–100 kB,把它分割成多个更小的包。(由于 HTTP/2 的多路复用特性,多个请求和响应可以同时到达,从而减少额外请求的负载。)
- 由于移动设备上的网络速度,你应该减少网络传输,而且也需要维持更低的内存使用。
- 提升执行速度
- 避免大型内联脚 因为它们也会在主线程中解析和编译)。一个不错的规定是:如果脚本超过 1KB,就不要将其内联(外部脚本的字节码缓存要求最小为 1KB 也是一个原因)。
为何优化下载和执行时间很重要? #
为何优化下载和执行时间很重要?下载时间在低端网络环境下很关键。尽管 4G(甚至 5G)在全球范围快速发展,我们实际感受到的网络速度和宣传并不一致,很多时候感觉就像 3G(甚至更差)。
JavaScript 执行时间在使用低端 CPU 的手机上很重要。由于 CPU、GPU 和散热上的差异,不同手机上性能差异非常大。这会影响到 JavaScript 的性能,因为 JavaScript 的执行是 CPU 密集型任务。
实际上,像 Chrome 这样的浏览器上的页面加载总时间,有多达 30% 的时间花在 JavaScript 执行上。下面是一个任务负载(Reddit.com)很典型的网站在高端桌面设备上的页面加载, V8 中的 JavaScript 处理占用了页面加载时间的 10-30%。
V8 中的 JavaScript 处理占用了页面加载时间的 10-30%。
移动设备上,中端机(Moto G4)的 JavaScript 执行时间是高端机(Pixel 3)的 3 到 4 倍,低端机(不到 100 刀的 Alcatel 1X)上有超过 6 倍的性能差异: Reddit 在不同设备类型上(低端、中端和高端)的 JavaScript 性能损耗
Reddit 在不同设备类型上(低端、中端和高端)的 JavaScript 性能损耗
注意: Reddit 在桌面端和移动端的体验完全不同,因此 MacBook Pro 上的结果并不能和其他设备上的结果直接做比较。
当你尝试优化 JavaScript 执行时间,注意关注长任务,它可能长期独占 UI 线程。这些任务会阻塞执行关键任务,即便页面看起来已经加载完成。把长任务拆分成多个小任务。通过代码分割和指定加载优先级,可以提升页面可交互速度,并且有希望降低输入延迟。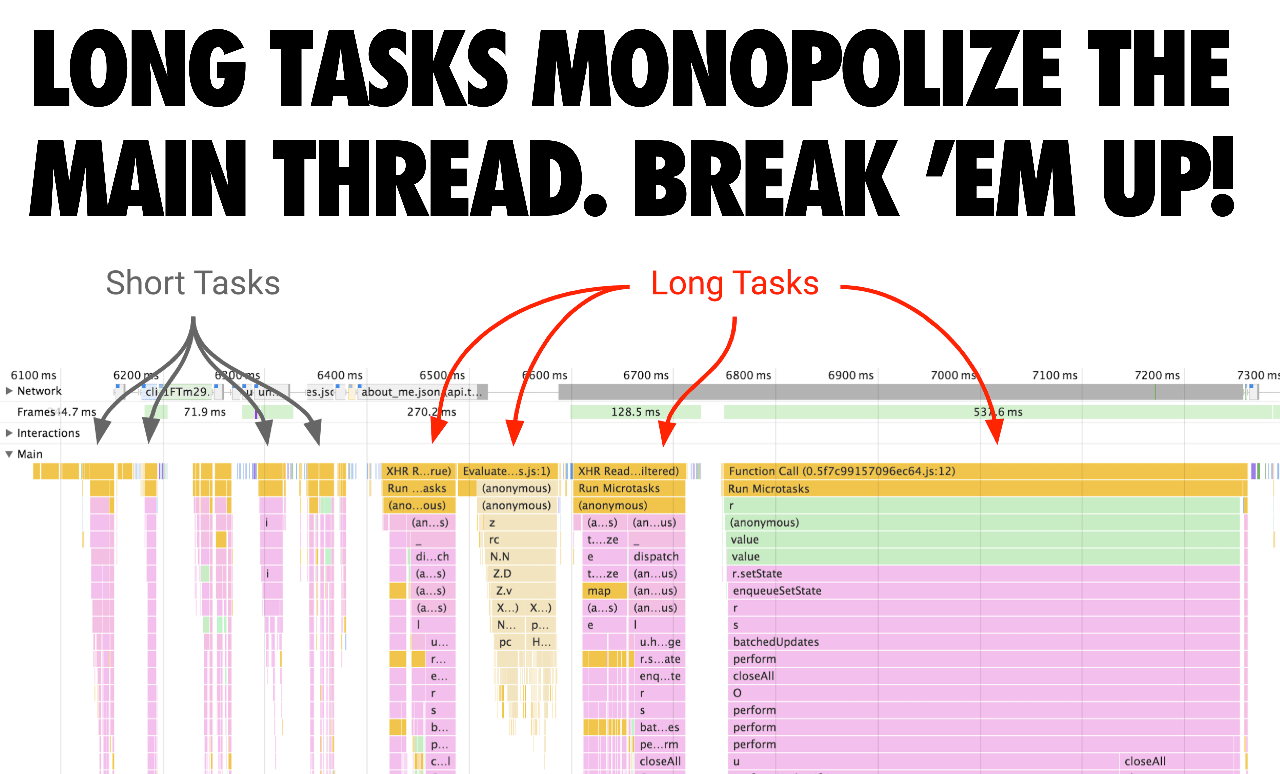 长任务独占主线程,应该拆分它们。
长任务独占主线程,应该拆分它们。
V8 在提升解析编译速度上做了什么? #
Chrome 60+ 上,V8 对于初始 JavaScript 的解析速度提升了 2 倍。与此同时, 由于 Chrome 上的其他并行优化,初始解析和编译的性能损耗更少了。
V8 减少了主线程上的解析编译任务,平均减少了 40%(比如 Facebook 上是 46%,Pinterest 上是 62%),最高减少了 81%(YouTube),这得益于将解析编译任务搬到了 worker 线程上。这对于流式解析/编译是一个补充。 不同 V8 版本上的解析时间
不同 V8 版本上的解析时间
下图形象呈现了不同 Chrome V8 版本上 CPU 解析时间。Chrome 61 解析 Facebook 的 JS 花了相同的时间,Chrome 75 现在解析 Facebook 的时间是 Twitter 的 6 倍。 Chrome 61 解析 Facebook 的 JS 时间,Chrome 75 可以同时解析 Facebook 和 6次 Twitter 的 JS。
Chrome 61 解析 Facebook 的 JS 时间,Chrome 75 可以同时解析 Facebook 和 6次 Twitter 的 JS。
我们来研究下这些释放出来的改变。长话短说,流式解析和 worker 线程编译脚本,这意味着:
- V8 可以解析编译 JavaScript 时不阻塞主线程。
- 流式解析始于整个 HTML 解析器遇到
<script> 标签。对于阻塞解析的脚本,HTML 解析器会暂停,而异步脚本会继续执行。 - 对于大多数真实世界的网络连接速度,V8 解析比下载快,因此 V8 在脚本下载完后很快就完成了解析编译。
稍微解释下...很老的 Chrome 上会在完整下载完脚本后才开始解析,这很直接但并没有完全利用好 CPU。Chrome 41 和 68 之间的版本上,Chrome 在下载一开始就在一个独立线程上解析 async 和 defer 的脚本。 页面上的脚本被分割成多个块。只要代码块超过 30KB,V8 就会开始流式解析。
页面上的脚本被分割成多个块。只要代码块超过 30KB,V8 就会开始流式解析。
Chrome 71 上,我们开始做一个基于任务的调整,调度器可以一次解析多个 async/defer 脚本。这一改变的影响是,主线程解析时间减少 20%,在真实网站上,带来超过 2% 的 TTI/FID 提升。
译者注:FID(First Input Delay),第一输入延迟(FID)测量用户首次与您的站点交互时的时间(即,当他们单击链接,点击按钮或使用自定义的 JavaScript 驱动控件时)到浏览器实际能够的时间回应这种互动。交互时间(TTI)是衡量应用加载所需时间并能够快速响应用户交互的指标。
 Chrome 71 moved to a task-based setup where the scheduler could parse multiple async/deferred scripts at once.
Chrome 71 moved to a task-based setup where the scheduler could parse multiple async/deferred scripts at once.Chrome 72 上,我们转向使用流式解析作为主要解析方式:现在一般异步的脚本都以这种方式解析(内联脚本除外)。我们也停止了废除基于任务的解析,如果主线程需要的话,因为那样只是在做不必要的重复工作。
早期版本的 Chrome 支持流式解析和编译,来自网络的脚本源数据必须先到达 Chrome 的主线程,然后才会转发给流处理器。
这常会造成流式解析器等待早已下载完成但还没有被转发到流任务的数据,因为它被主线程上的其他任务(比如 HTML 解析,布局或者 JavaScript 执行)所阻塞。
我们现在正在尝试开始对预加载进行解析,而主线程弹跳会事先对此形成阻塞。
Leszek Swirski 的 BlinkOn 演示呈现了更多细节:“Parsing JavaScript in zero* time” as presented by Leszek Swirski at BlinkOn 10.
除了上述之外,DevTools 有个问题,它暗中使用了 CPU,这会影响到整个解析任务的呈现。然而,解析器解析数据时就会阻塞(它需要在主线程上运行)。自从我们从一个单一的流处理线程中移动到流任务中,这一点就变成更为明显了。下面是你在 Chrome 69 中经常会看到的: The DevTools issue that rendered the entire parser task in a way that hints that it’s using CPU (full block)
The DevTools issue that rendered the entire parser task in a way that hints that it’s using CPU (full block)
上图中的“解析脚本”任务花了 1.08 秒。而解析 JavaScript 其实并不慢!多数时间里除了等待数据通过主线程之外什么都不做。
Chrome 76 的表现大不相同: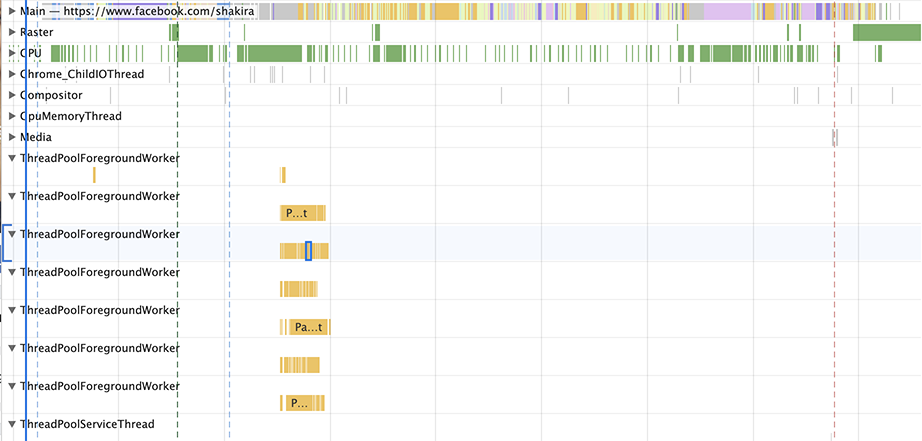 Chrome 76 上,解析脚本被拆分成多个更小的流式任务。
Chrome 76 上,解析脚本被拆分成多个更小的流式任务。
通常,DevTools 性能面板很适合用来查看页面上发生的行为。对于更详细的 V8 特定指标,比如 JavaScript 解析编译时间,我们推荐使用带有运行时调用统计(RCS)的 Chrome Tracing。RCS 结果中,Parse-Background 和 Compile-Background 代表主线程之外解析和编译 JavaScript 花费的时间,然而 Parse 和 Compile 记录了主线程的指标。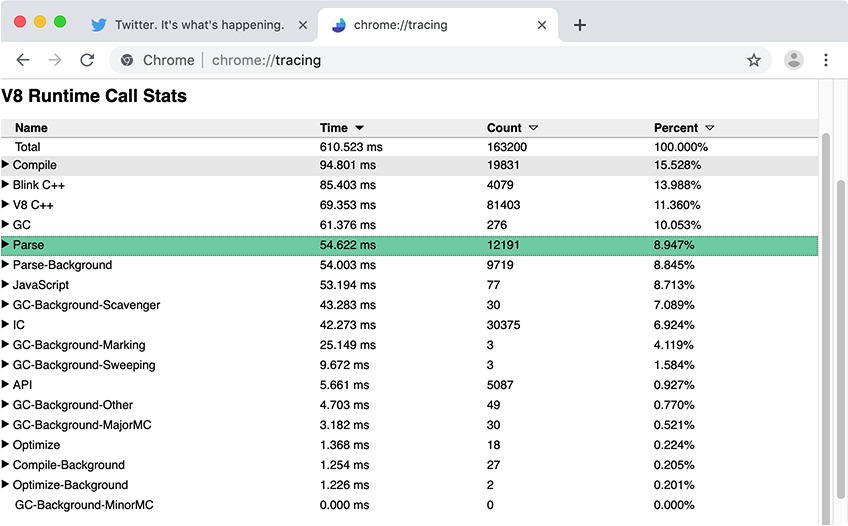
这些改变的真实影响? #
来看一些真实网站的例子和脚本流式解析如何应用。 在 MacBook Pro 上,主线程和 worker 线程解析编译 Reddit 的 JS 所花的时间。
在 MacBook Pro 上,主线程和 worker 线程解析编译 Reddit 的 JS 所花的时间。
Reddit.com 有多个 100 KB+ 的代码包,这些包被包装在引起主线程大量懒编译的外部函数中。在上图中,由于主线程忙碌会延迟可交互时间,其运行时间至关重要。Reddit 花了多数时间在主线程上,Work/Background 线程的利用率很低。
这得益于将大包分割成多个小包(比如每个 50KB),以达到最大并行化,从而每个包都可以被独立地流式解析编译,减轻主线程在启动阶段的压力。 Facebook 在 Macbook Pro 上的主线程和 worker 线程解析编译时间对比
Facebook 在 Macbook Pro 上的主线程和 worker 线程解析编译时间对比
再来看看 Facebook.com。Facebook通过 292 个请求加载了 6MB 压缩后的 JS,其中有些是异步的,有些是预加载的,还有些的加载优先级较低。它们很多 JavaScript 的粒度都非常小 - 这对 Background/Worker 线程上的整体并行化很有用,因为这些小的 JavaScript 可以同时被流式解析编译。
注意,你可能不是 Facebook,很可能没有一个类似 Facebook 或者 Gmail 这样的长寿应用,在桌面端,它们放如此多的 JavaScript 是无可非议的。然而,一般来说,应该让你的包的粒度较粗,并且按需加载。
尽管多数 JavaScript 解析编译任务可以在 background 线程中以流的形式完成,但是某些任务仍然必须要在主线程中进行。当主线程忙碌时,页面不能响应用户输入。注意关注下载执行代码对你的用户体验造成的影响。
注意: 当下,不是所有的 JavaScript 引擎和浏览器都实现了 script streaming 来优化加载。但我们相信大家为了优秀用户体验会加入这项优化的。
解析 JSON 的性能损耗 #
由于 JSON 语法比 JavaScript 语法简单得多,解析 JSON 也会更快。这一点可以用于提升 web 应用的启动性能,我们可以使用类似 JSON 的对象字面量配置(比如内联 Redux store)。不要使用 JavaScript 对象字面量来内联数据,比如这样:
const data = { foo: 42, bar: 1337 };
…它可以被表示成字符串化的 JSON 格式,运行时会变成解析后的 JSON:
const data = JSON.parse('{"foo":42,"bar":1337}');
若 JSON 字符串只被执行一次,尤其是在冷启动阶段,JSON.parse 方法相比 JavaScript 对象字面量会快得多。在大于 10 KB 的对象上使用这个技巧的效果更佳 - 但在实际应用前,还是先要测试下真实效果。
JSON.parse('…') is much faster to parse, compile, and execute compared to an equivalent JavaScript literal — not just in V8 (1.7× as fast), but in all major JavaScript engines.
在大型数据上使用普通对象字面量还有个风险:它们可能被解析两次!
The following video goes into more detail on where the performance difference comes from, starting at the 02:10 mark.“Faster apps with JSON.parse” as presented by Mathias Bynens at #ChromeDevSummit 2019.
See our JSON ⊂ ECMAScript feature explainer for an example implementation that, given an arbitrary object, generates a valid JavaScript program that JSON.parses it.
There’s an additional risk when using plain object literals for large amounts of data: they could be parsed twice!
- 第一次发生于字面量预解析阶段。
- 第二次发生于字面量懒解析阶段。
第一次解析无法避免。幸运地,第二次可以通过将对象字面量放在顶层来避免,或者放在 PIFE.
关于重复访问上的解析/编译? #
V8 的字节码缓存优化大有帮助。当首次请求 JavaScript,Chrome 下载然后将其交给 V8 编译。Chrome 也会将文件存进浏览器的磁盘缓存中。当 JS 文件再次请求,Chrome 从浏览器缓存中将其取出,并再次将其交给 V8 编译。这个时候,编译后代码是序列化后的,会作为元数据被添加到缓存的脚本文件上。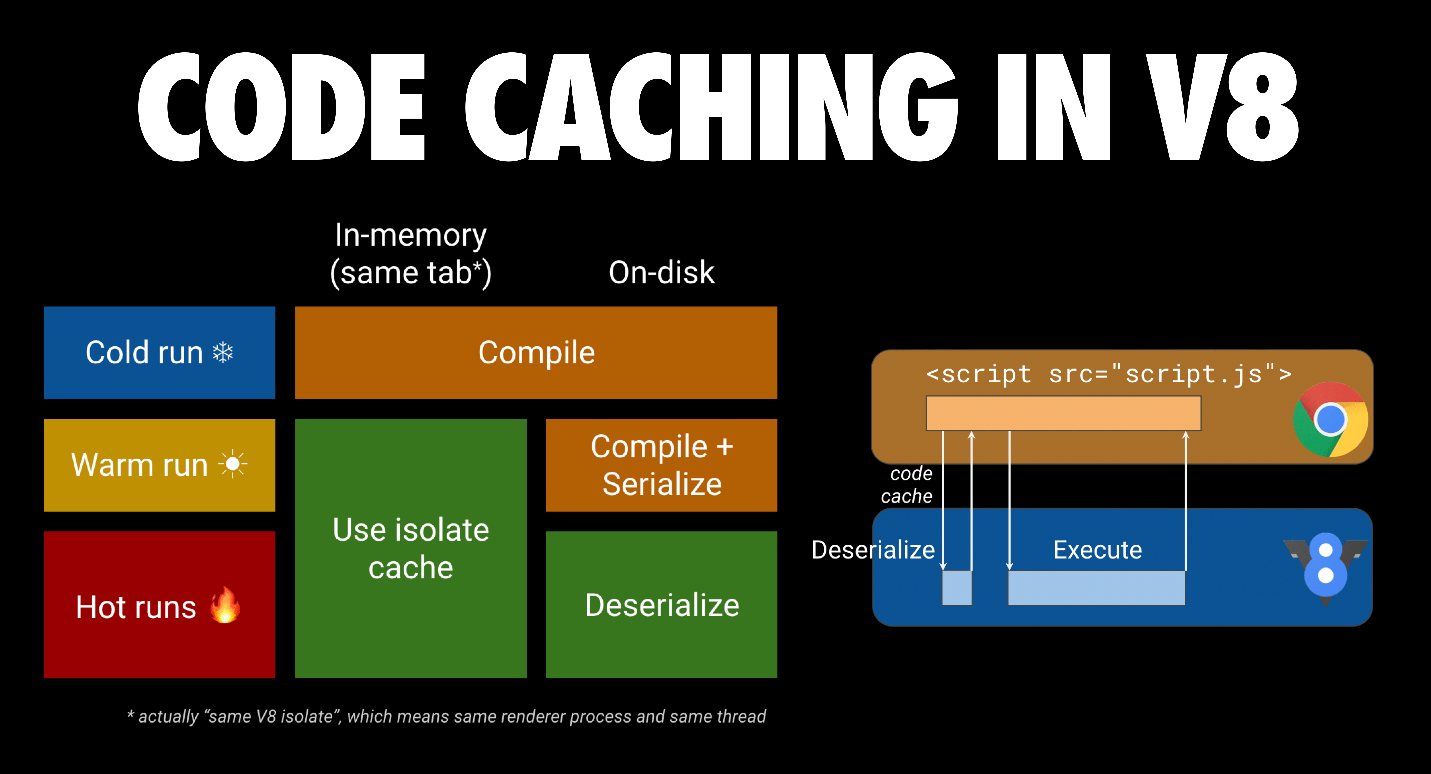 V8 中的字节码缓存工作示意图
V8 中的字节码缓存工作示意图
第三次,Chrome 将文件和文件元数据从缓存中取出,一起交给 V8 处理。V8 对元数据作反序列化,这样可以跳过编译。字节码缓存会在 72 小时内的前两次访问生效。配合使用 service worker 来缓存 JavaScript 代码,Chrome 的字节码缓存效果更佳。你可以在给开发者讲的字节码缓存这篇文章中了解到更多细节。
结论 #
2019 年,下载和执行时间是加载 JavaScript 的主要瓶颈。首屏展示内容里使用异步的(内联)JavaScript的小型包,页面剩下部分使用延迟(deferred)加载的 JavaScript。分解大型包,实现代码按需加载。这样可以最大化 V8 中的并行解析。
移动设备上,考虑到网络、内存使用和低端 CPU 上的执行时间,你应该传输更少的 JavaScript。平衡可缓存性和延迟,实现在主线程之外解析编译任务数量的最大化。
进一步阅读 #