本文我们将解释 V8 内部如何处理 JavaScript 属性(properties)。从 JavaScript 的角度来看属性只有少数的区别。JavaScript 对象通常跟字典(dictionaris)差不多,以字符串为键,任意对象为值。尽管规范确实对迭代过程中的整数索引属性与其他属性作了区分,但除此以外,不同属性表现基本是一致的,不管是不是整数索引。
然而,在底层 V8 的确依赖了一些不同的属性表示方式,这是出于性能和内存考虑的。本文我们将解释 V8 如何在提供快属性访问的同时支持动态添加属性。理解属性如何工作对解释 V8 内联缓存之类的优化原理是必不可少的。
本文解释了整数索引与命名属性的不同处理方式。随后我们展示了 V8 如何在添加命名属性同时维护隐藏类(HiddenClasses),以提供快速的方式识别一个对象的形状(shape)。接着我们继续深入了解命名属性是如何根据使用方式来进行优化,以支持快速访问和快速修改。最后部分我们详细介绍了 V8 如何处理整数索引属性或数组索引。
命名属性与元素 #
首先我们来分析一个简单的对象 {a: "foo", b: "bar"}。这个对象有两个命名属性,"a" 和 "b",没有任何整数索引作属性名。数组索引属性(array-indexed properties),常叫元素(elements),在数组中非常重要。比如数组 ["foo", "bar"] 有两个数组索引属性:0 与值 "foo" ,和 1 与值 "bar"。 这是 V8 如何处理属性的第一个主要区别。
下图展示了一个基本 JavaScript 对象在内存中是什么样的。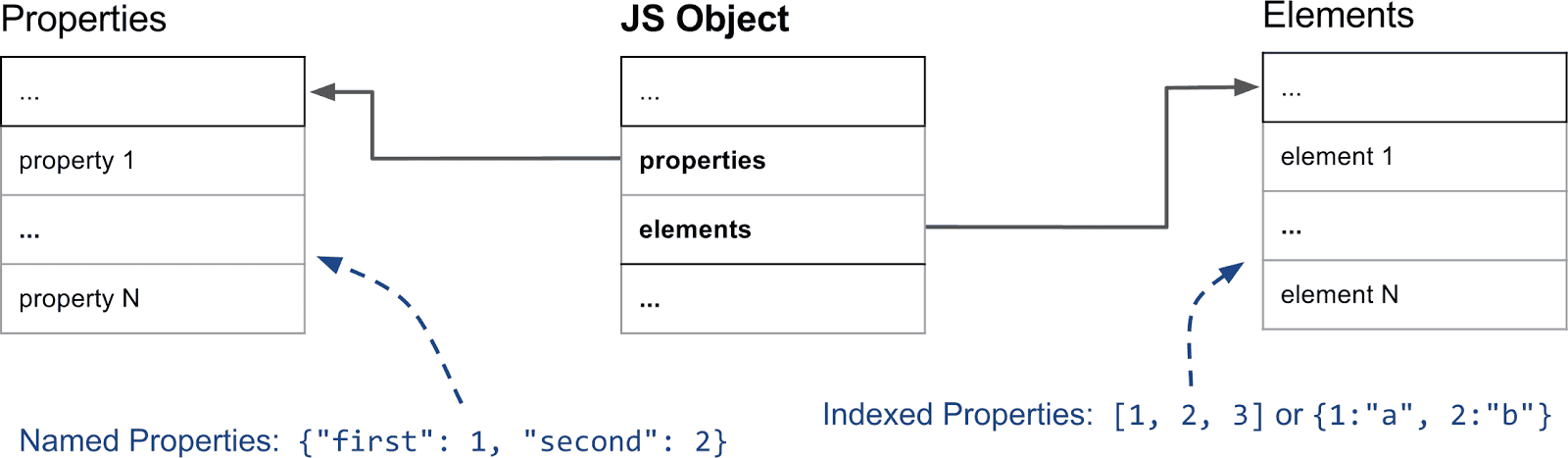
元素和属性被保存在两个独立的数据结构中。两者的使用方式通常不一样,故这能让添加和访问属性或元素更加高效。
元素主要被用在各种 Array.prototype 方法中,如 pop 或者 slice。考虑到这些函数都是连续地访问属性,V8 内部还将它们表示为简单的数组,大多数情况下都是如此。本文后面还会解释到有时我们如何切换到基于稀疏字典的表示来节省内存。
命名属性也是通过类似的方式存在另外的数组中。但是,跟元素不同,我们不能简单地通过键来推断出它们在属性数组中的位置,我们需要一些额外的元数据。在 V8 中每个 JavaScript 对象都关联了一个隐藏类(HiddenClasses)。隐藏类保存了对象的形状信息,以及从属性名称到属性索引的映射。复杂的使用情况下我们有时会用字典来存属性而不是简单的数组。我们会在专门的部分再作详细地解释。
本节要点:
- 数组索引属性被保存在独立的元素存储中。
- 命名属性被保存在属性存储中。
- 元素和属性可以是数组或者字典。
- 每个 JavaScript 对象都有相应的隐藏类来记录该对象的形状信息。
隐藏类和描述符数组 #
在解释了元素和命名属性的一般区别之后,我们需要看看隐藏类在 V8 中是如何工作的。隐藏类保存了与对象相关的元信息,包括对象上的属性数和对象原型的引用。隐藏类在概念上与典型面向对象编程语言中的类相似。但是,在基于原型的语言(如 JavaScript)中,通常不可能预先知道类。因此,在这种情况下,V8 的隐藏类是动态创建的,并随着对象的变化而动态更新。隐藏类充当了对象形状的标识符,因此是 V8 优化编译器和内联缓存非常重要的组成部分。比如优化编译器可以直接内联属性访问,如果它可以通过隐藏类来确保对象结构是兼容的。
我们来看看隐藏类的重要部分。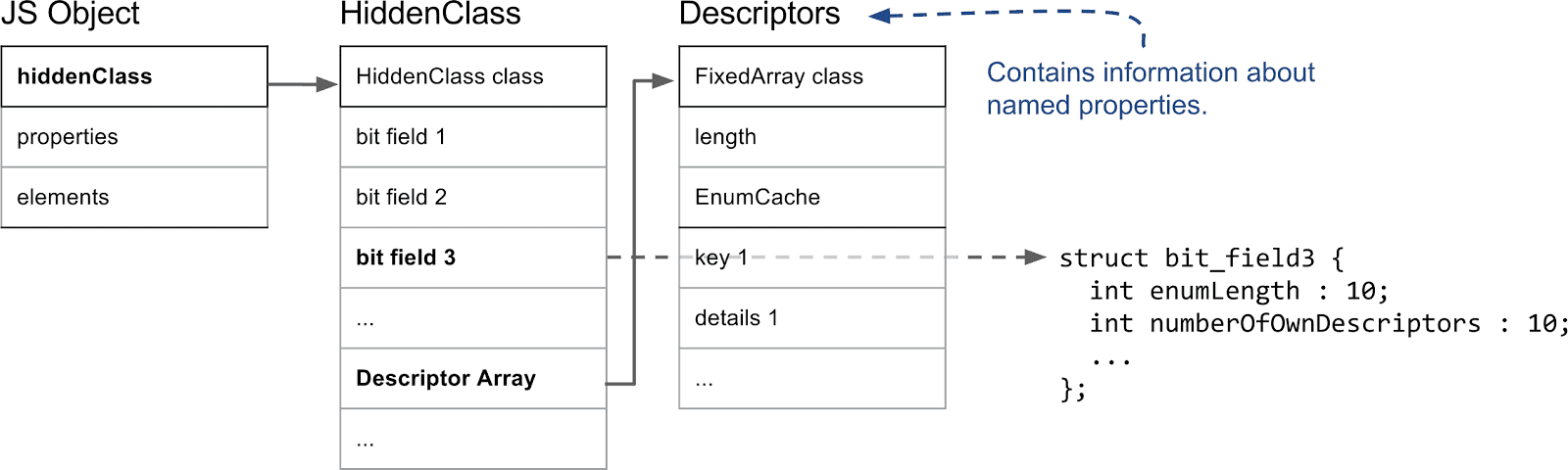
在 V8 中,JavaScript 对象的第一个字段指向隐藏类(事实上,任何在 V8 堆上且由垃圾收集器管理的对象都是这种情况)。在属性中,最重要的信息是第三位字段,它保存了属性数以及描述符数组的指针。描述符数组包含了有关命名属性的信息,例如名称本身以及值保存的位置。注意我们不会在此处跟踪整数索引属性,故描述符数组中没有相关条目。
对于隐藏类的基本判断标准是,具有相同结构的对象(如属性命名相同且顺序相同)共享相同的隐藏类。为了实现这一点,对象在添加属性后我们将使用不同的隐藏类。在下面的示例中,我们从一个空对象开始并添加三个命名属性。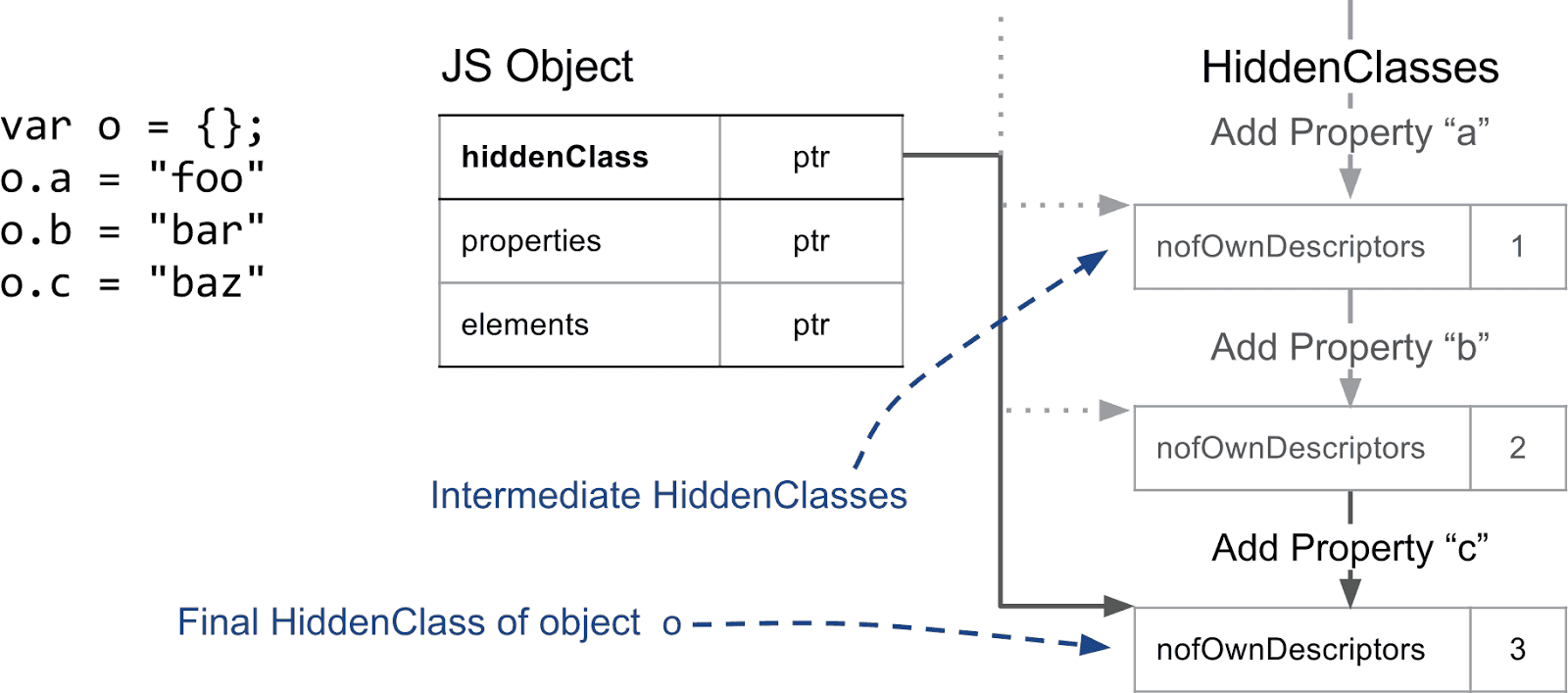
每次添加新属性时,对象的隐藏类都会被更改。在引擎的底层,V8 创建了一个将隐藏类链接在一起的转换树(transiton tree)。当你向一个空对象添加属性(如“a”)时,V8 会知道要采用哪个隐藏类。如果以相同的顺序添加相同的属性,此转换树会确保最后得到的是相同的最终隐藏类。以下示例显示,即使我们在其间添加了简单的索引属性,我们还是得到了相同的转换树。
然而,如果我们创建一个添加了不同属性的新对象,如属性 "d",则 V8 会为新的隐藏类创建一个单独的分支。
本节要点:
- 具有相同结构的对象(相同顺序相同属性)具有相同的隐藏类。
- 默认情况下,每添加新的命名属性都会导致一个新的隐藏类被创建。
- 添加数组索引属性不会创建新的隐藏类。
三种不同的命名属性 #
在概述了 V8 如何使用隐藏类跟踪对象的形状之后,让我们深入了解这些属性的实际存储方式。正如上面介绍中所解释的,属性有两种基本类型:命名和索引。以下部分先介绍命名属性。
一个简单的对象如 {a:1,b:2} 在 V8 中可以有多种内部表示。虽然 JavaScript 对象在外部看来或多或少类似于简单的字典,但 V8 试图避免使用字典,因为它们妨碍了某些优化,如内联缓存,我们会在其它文章中再作解释。
对象与普通属性: V8 支持所谓的对象内属性(in-object properties),指这些属性直接存储在对象本身上。它们在 V8 可用的属性中是最快的,因为它们不需要间接层就可以访问。对象内属性的数量由对象的初始大小预先确定。如果添加的属性超出了对象分配的空间,则它们将被保存在属性存储中。属性存储多了一层间接层,但可以自由地扩容。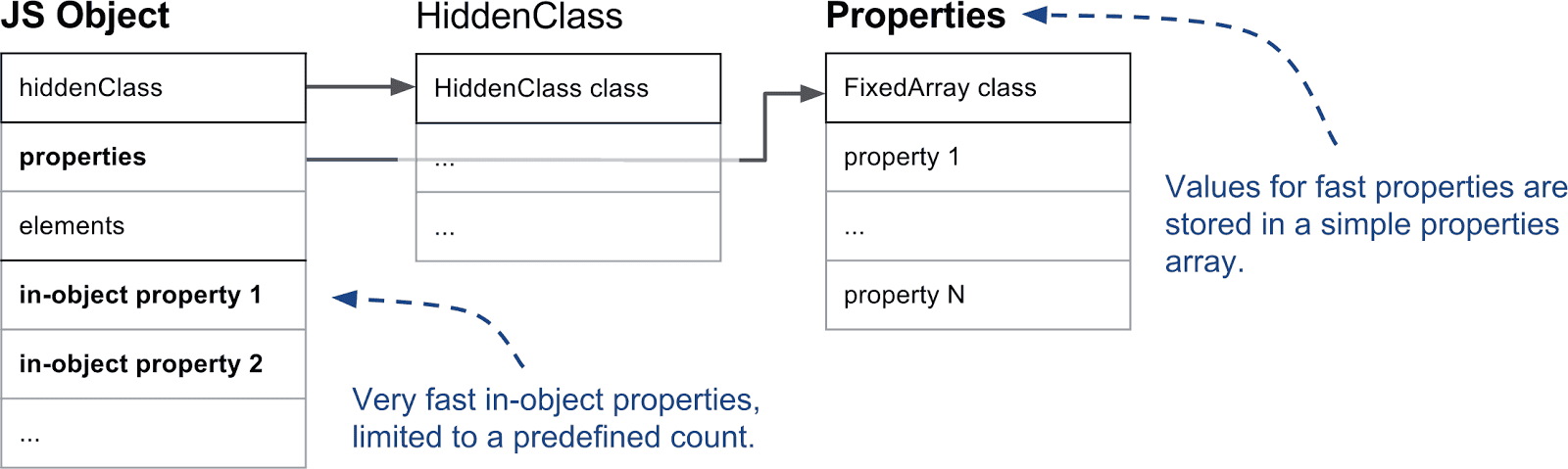
快属性与慢属性: 下一个重要区别是快属性和慢属性。通常,我们将保存在线性属性存储中的属性定义为“快”。只需通过属性存储中的索引即可访问快属性。要从属性名称获取属性存储中的实际位置,我们必须查看隐藏类上的描述符数组,如前面所述。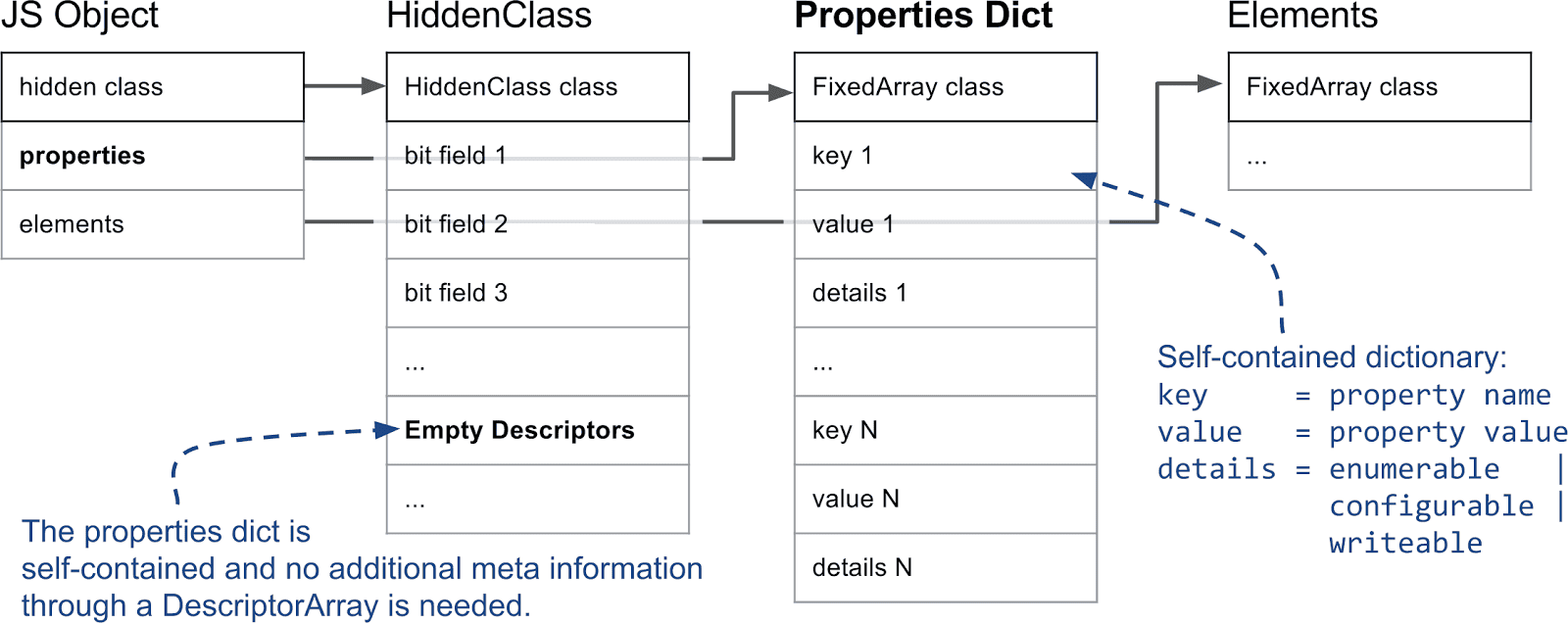
但是,如果从对象中添加和删除大量属性,则可能会产生大量时间和内存开销来维护描述符数组和隐藏类。因此 V8 还支持所谓的慢属性。带慢属性的对象内部会有独立的词典作为属性存储。所有的属性元信息不再保存在隐藏类的描述符数组中,而是直接保存在属性字典中。因此无需更新隐藏类即可添加和删除属性。由于内联缓存不适用于字典属性,故后者通常比快属性慢。
本节要点:
- 有三种不同的命名属性类型:对象内属性、快属性和慢属性(字典)。
- 对象属性直接保存在对象本身上,并提供最快的访问。
- 快属性保存在属性存储中,所有元信息都存储在隐藏类的描述符数组中。
- 慢属性保存在内部独立的属性字典中,不再通过隐藏类共享元信息。
- 慢属性允许高效的属性删除和添加,但访问速度比其它两种类型慢。
元素与数组索引属性 #
到目前为止,我们一直在讨论命名属性,而忽略了常用于数组的整数索引属性。处理整数索引属性并不比命名属性简单。尽管所有索引属性都是在元素存储中单独保存,但不同类型的元素也有 20 种!
挤满的还是带空隙的元素: V8 做的第一个主要区分看是元素后备存储(elements backing store)是挤满的(packed)还是带空隙的(holey)。当索引元素被删除,又或者如,没有被定义,后备存储中就会出现空隙。如一个简单的例子 [1,,3],其中的第二个条目就是一个空隙。以下示例说明了此问题:
const o = ['a', 'b', 'c'];
console.log(o[1]);
delete o[1];
console.log(o[1]);
o.__proto__ = {1: 'B'};
console.log(o[0]);
console.log(o[1]);
console.log(o[2]);
console.log(o[3]);
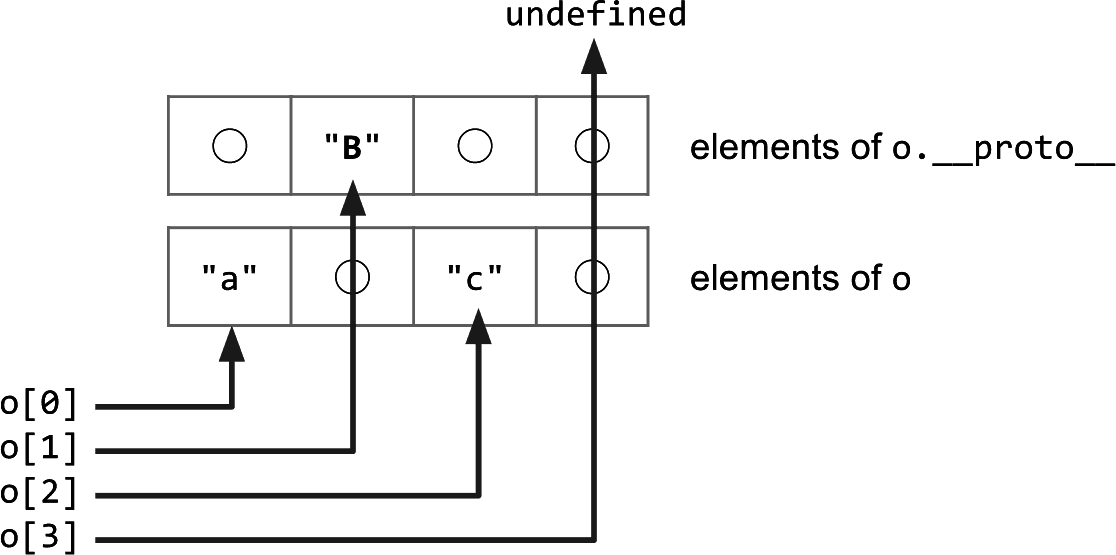
简而言之,如果接收方(receiver)上没有发现属性,我们就必须沿着原型链继续查找。鉴于元素是内部独立的(比如,我们不会在隐藏类上保存有关当前索引属性的信息),我们需要一个特殊值,称为 _hole,来标记不存在的属性。这对于数组函数的性能是至关重要的。如果我们知道没有空隙,即元素存储是挤满的,我们就可以直接在当前域执行操作而无需沿着原型链做昂贵的查找。
快元素还是字典元素: V8 对元素做的第二个主要区分是看它们是在快速模式还是字典模式。快元素是简单的虚拟机内部数组,其中的属性索引映射到元素存储中的索引。然而,这种简单的表示对于非常大的稀疏/带空隙的数组而言是相当浪费的,其中只有很少的条目被占用。在这种情况下,我们使用基于字典的表示来节省内存,但代价是访问速度稍慢:
const sparseArray = [];
sparseArray[9999] = 'foo';
在这个例子中,开辟一个包含一万条目的完整数组会相当浪费。相反,V8 会创建一个字典来存储键-值-描述符三元组。在这个例子中,键是 '9999',值是 'foo',默认描述符被使用。由于我们没有办法在隐藏类上保存描述符的详细信息,故只要你使用了自定义描述符去定义索引属性,V8 就会采用慢元素:
const array = [];
Object.defineProperty(array, 0, {value: 'fixed' configurable: false});
console.log(array[0]);
array[0] = 'other value';
console.log(array[0]);
在这个例子中,我们在数组上添加了一个不可配置的属性。该信息保存在慢元素字典三元组的描述符部分中。需要注意的是,在带有慢元素的对象上数组函数的执行速度会慢很多。
小整数和双浮点元素: 对于快元素,V8 中还有另一个重要的区分。比如一个常见的例子,只在一个数组中放整数,那么垃圾回收器就不必查看数组,因为整数被直接编码为所谓的小整数(Smis)。另一个特例是只包含双浮点数(double)的数组。与小整数不同,浮点数通常表示为占据多个字(word)的完整对象。然而,在 V8 中,纯双浮点数的数组会使用原生双精度浮点数来保存,以减少内存和性能开销。以下例子列出了小整数和双浮点元素的四个示例:
const a1 = [1, 2, 3];
const a2 = [1, , 3];
const b1 = [1.1, 2, 3];
const b2 = [1.1, , 3];
特殊元素: 到目前为止,我们已经涵盖了 20 种不同元素中的 7 种。为简单起见,我们排除了 9 种 TypedArrays 相关的元素类型,2 种 String 包装器相关的,还有 2 种参数对象相关的特殊类型。
元素访问器: 正如你所想的,我们并不太热衷于在 C++ 中给元素种类一个个对应地写 20 多遍数组函数。这里就需要一些 C++ 魔术。我们不是一遍又一遍地实现数组函数,而是构建了元素访问器 ElementsAccessor,这样我们大多情况下只需要实现简单的函数来从后备存储中访问元素。ElementsAccessor 依赖于 CRTP 来创建每个数组函数的专用版本。因此,如果在数组上调用类似 slice 的方法,V8 内部会调用 C++ 编写的内置函数,并通过 ElementsAccessor 调度到函数的专用版本: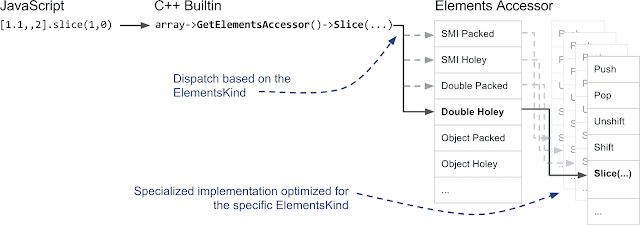
本节要点:
- 索引属性和元素有快速和字典模式。
- 快属性可以是挤满的(packed),也可以包含空隙(holes)表示索引属性被删除。
- 不同类型的元素根据其内容专门优化,以加速数组函数并减少垃圾回收器开销。
了解属性如何工作是 V8 中许多优化的关键。对于 JavaScript 开发者来说,许多这样的内部决策都不是直接可见的,但它们解释了为什么某些代码模式比其它的更快。更改属性或元素类型通常会导致 V8 创建一个不同的隐藏类,这可能导致类型污染阻止 V8 生成最优代码。请继续关注有关 V8 虚拟机内部工作原理的更多文章。