Proxies have been an integral part of JavaScript since ES2015. They allow intercepting fundamental operations on objects and customizing their behavior. Proxies form a core part of projects like jsdom and the Comlink RPC library. Recently, we put a lot of effort into improving the performance of proxies in V8. This article sheds some light on general performance improvement patterns in V8 and for proxies in particular.
Proxies are “objects used to define custom behavior for fundamental operations (e.g. property lookup, assignment, enumeration, function invocation, etc.)” (definition by MDN). More info can be found in the full specification. For example, the following code snippet adds logging to every property access on the object:
const target = {};
const callTracer = new Proxy(target, {
get: (target, name, receiver) => {
console.log(`get was called for: ${name}`);
return target[name];
}
});
callTracer.property = 'value';
console.log(callTracer.property);
Constructing proxies #
The first feature we'll focus on is the construction of proxies. Our original C++ implementation here followed the ECMAScript specification step-by-step, resulting in at least 4 jumps between the C++ and JS runtimes as shown in the following figure. We wanted to port this implementation into the platform-agnostic CodeStubAssembler (CSA), which is executed in the JS runtime as opposed to the C++ runtime.This porting minimizes that number of jumps between the language runtimes. CEntryStub and JSEntryStub represent the runtimes in the figure below. The dotted lines represent the borders between the JS and C++ runtimes. Luckily, lots of helper predicates were already implemented in the assembler, which made the initial version concise and readable.
The figure below shows the execution flow for calling a Proxy with any proxy trap (in this example apply, which is being called when the proxy is used as a function) generated by the following sample code:
function foo(…) { … }
const g = new Proxy({ … }, {
apply: foo,
});
g(1, 2);
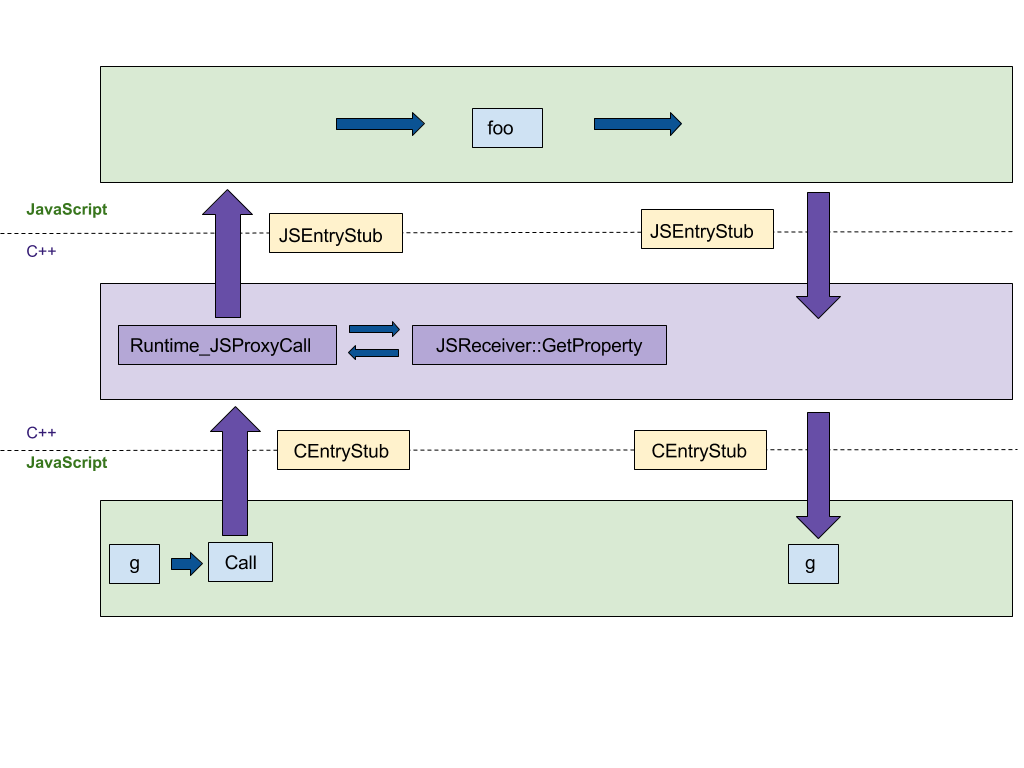
After porting the trap execution to CSA all of the execution happens in the JS runtime, reducing the number of jumps between languages from 4 to 0.
This change resulted in the following performance improvements::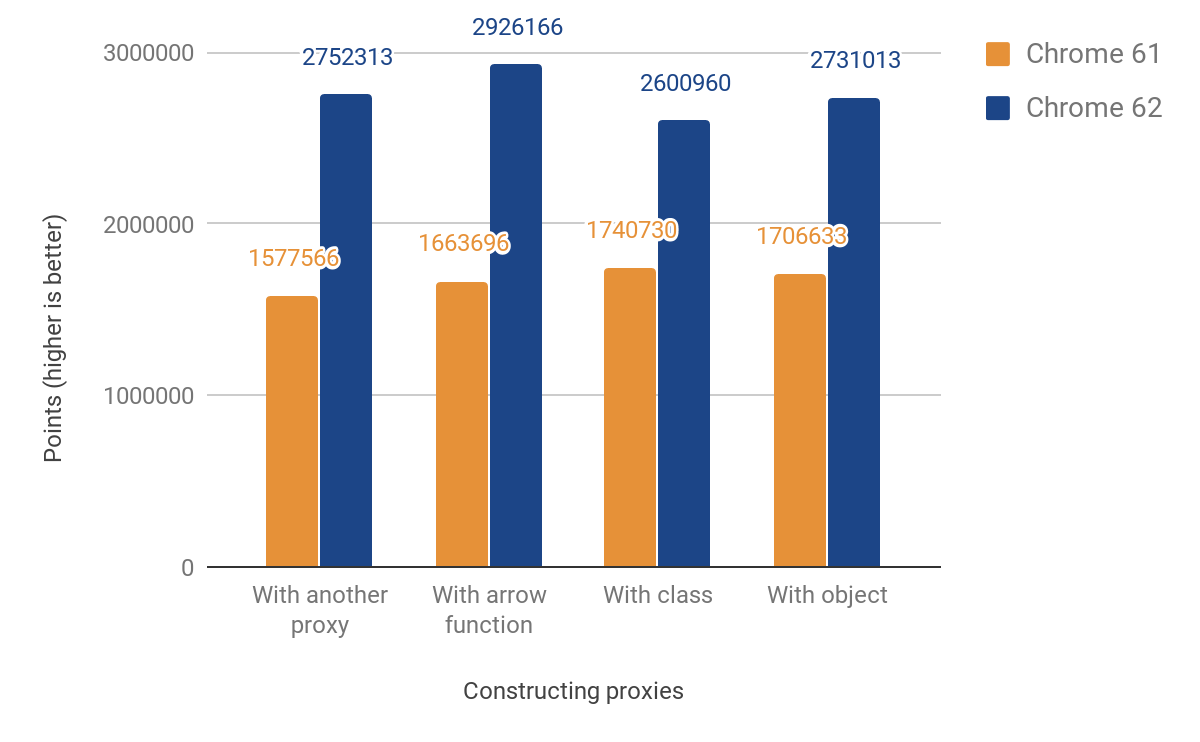
Our JS performance score shows an improvement between 49% and 74%. This score roughly measures how many times the given microbenchmark can be executed in 1000ms. For some tests the code is run multiple times in order to get an accurate enough measurement given the timer resolution. The code for all of the following benchmarks can be found in our js-perf-test directory.
Call and construct traps #
The next section shows the results from optimizing call and construct traps (a.k.a. "apply"" and "construct").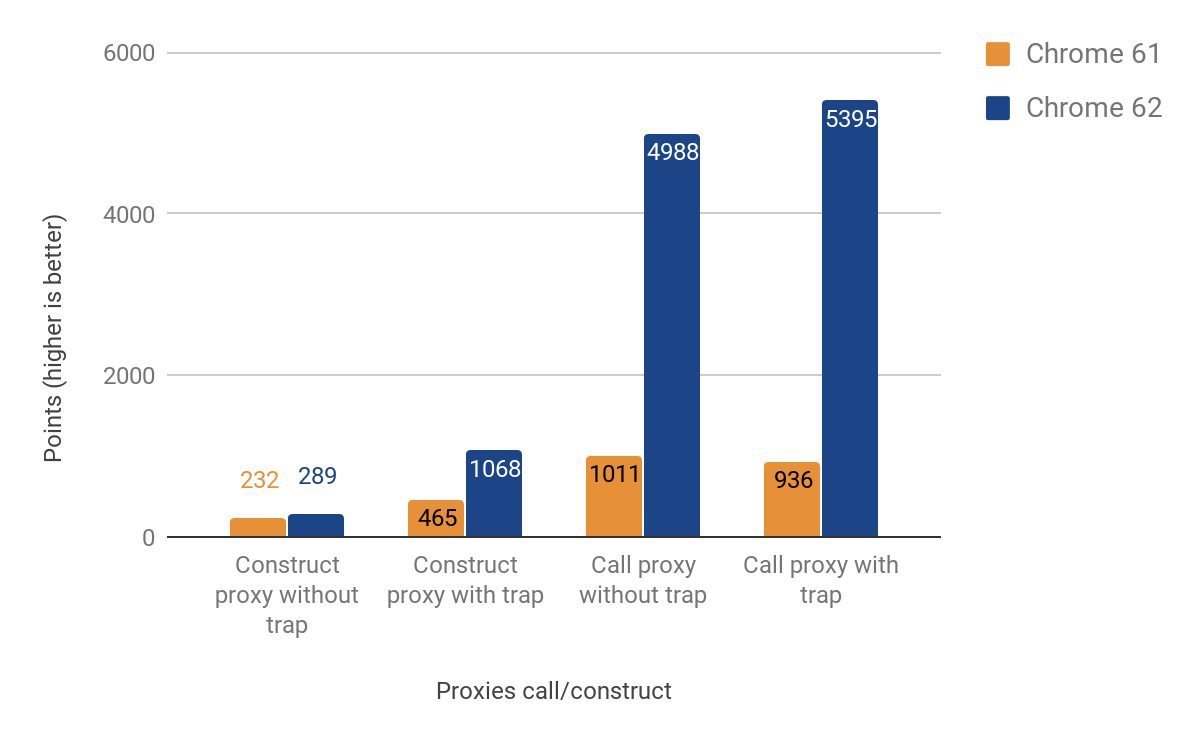
The performance improvements when calling proxies are significant — up to 500% faster! Still, the improvement for proxy construction is quite modest, especially in cases where no actual trap is defined — only about 25% gain. We investigated this by running the following command with the d8 shell:
$ out/x64.release/d8 --runtime-call-stats test.js
> run: 120.104000
Runtime Function/C++ Builtin Time Count
========================================================================================
NewObject 59.16ms 48.47% 100000 24.94%
JS_Execution 23.83ms 19.53% 1 0.00%
RecompileSynchronous 11.68ms 9.57% 20 0.00%
AccessorNameGetterCallback 10.86ms 8.90% 100000 24.94%
AccessorNameGetterCallback_FunctionPrototype 5.79ms 4.74% 100000 24.94%
Map_SetPrototype 4.46ms 3.65% 100203 25.00%
… SNIPPET …
Where test.js’s source is:
function MyClass() {}
MyClass.prototype = {};
const P = new Proxy(MyClass, {});
function run() {
return new P();
}
const N = 1e5;
console.time('run');
for (let i = 0; i < N; ++i) {
run();
}
console.timeEnd('run');
It turned out most of the time is spent in NewObject and the functions called by it, so we started planning how to speed this up in future releases.
Get trap #
The next section describes how we optimized the other most common operations — getting and setting properties through proxies. It turned out the get trap is more involved than the previous cases, due to the specific behavior of V8's inline cache. For a detailed explanation of inline caches, you can watch this talk.
Eventually we managed to get a working port to CSA with the following results: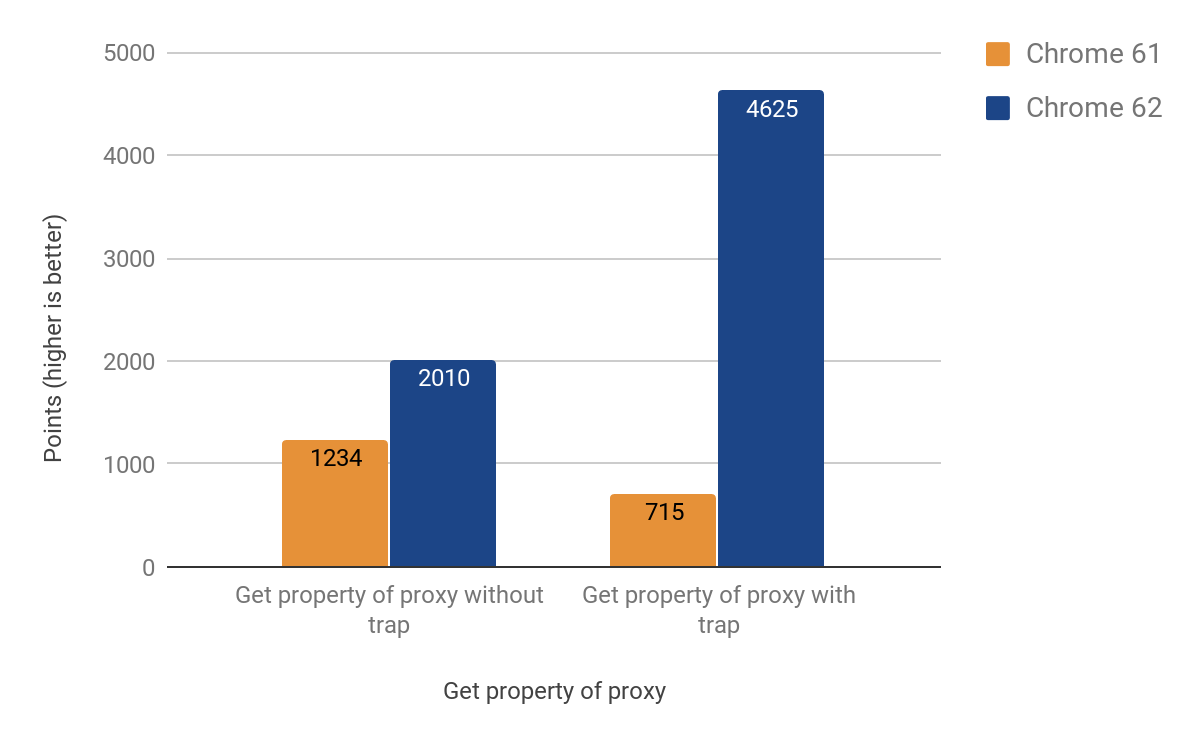
After landing the change, we noticed the size of the Android .apk for Chrome had grown by ~160KB, which is more than expected for a helper function of roughly 20 lines, but fortunately we track such statistics. It turned out this function is called twice from another function, which is called 3 times, from another called 4 times. The cause of the problem turned out to be the aggressive inlining. Eventually we solved the issue by turning the inline function into a separate code stub, thus saving precious KBs — the end version had only ~19KB increase in .apk size.
Has trap #
The next section shows the results from optimizing the has trap. Although at first we thought it would be easier (and reuse most of the code of the get trap), it turned out to have its own peculiarities. A particularly hard-to-track-down problem was the prototype chain walking when calling the in operator. The improvement results achieved vary between 71% and 428%. Again the gain is more prominent in cases where the trap is present.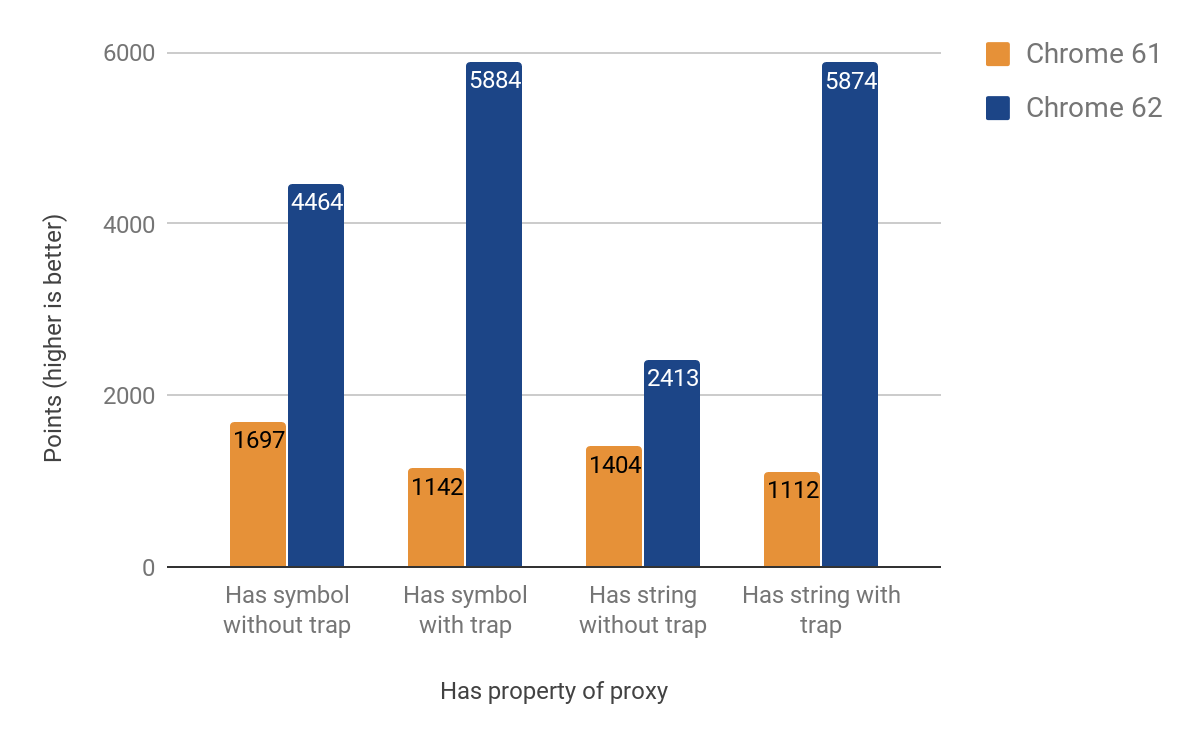
Set trap #
The next section talks about porting the set trap. This time we had to differentiate between named and indexed properties (elements). These two main types are not part of the JS language, but are essential for V8's efficient property storage. The initial implementation still bailed out to the runtime for elements, which causes crossing the language boundaries again. Nevertheless we achieved improvements between 27% and 438% for cases when the trap is set, at the cost of a decrease of up to 23% when it's not. This performance regression is due to the overhead of additional check for differentiating between indexed and named properties. For indexed properties, there is no improvement yet. Here are the complete results: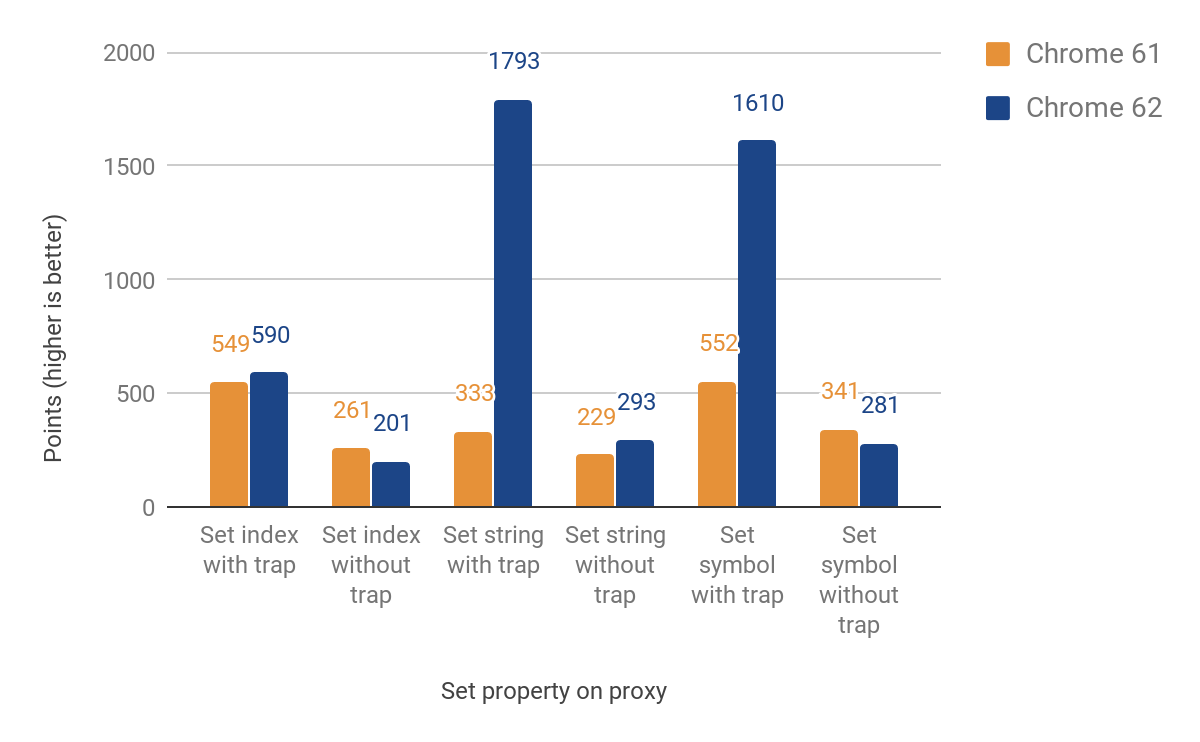
Real-world usage #
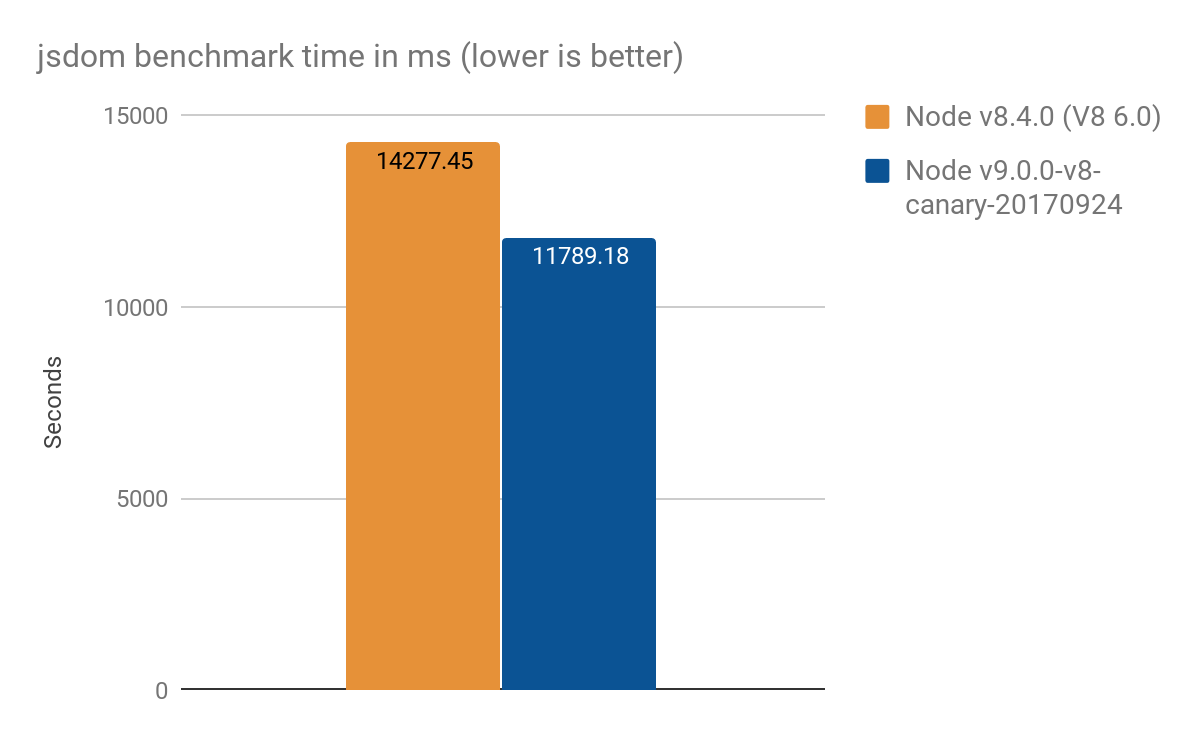
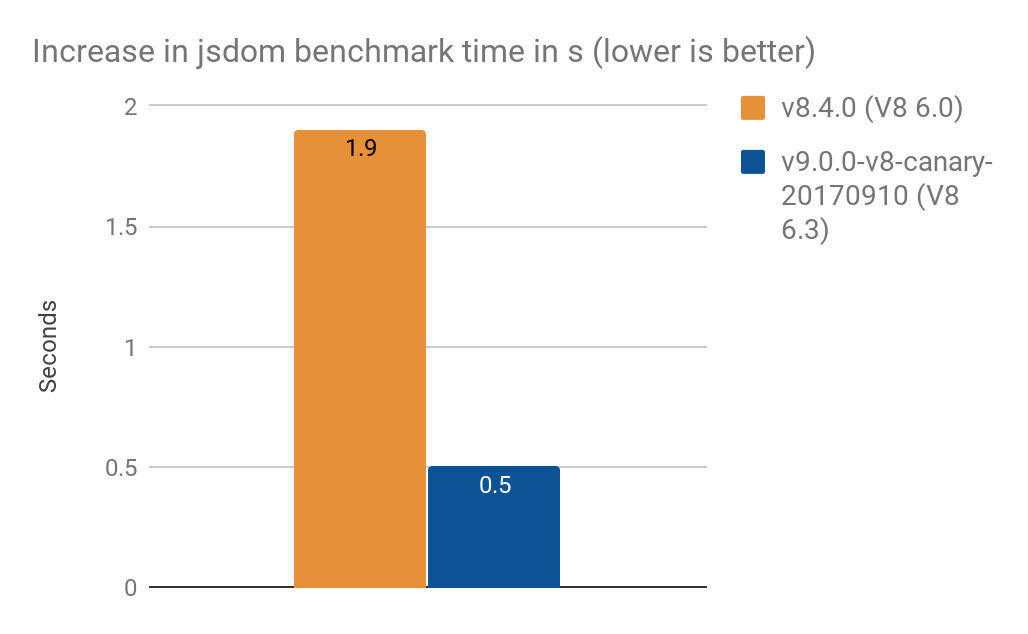
The jsdom-proxy-benchmark project compiles the ECMAScript specification using the Ecmarkup tool. As of v11.2.0, the jsdom project (which underlies Ecmarkup) uses proxies to implement the common data structures NodeList and HTMLCollection. We used this benchmark to get an overview of some more realistic usage than the synthetic micro-benchmarks, and achieved the following results, average of 100 runs:
- Node v8.4.0 (without Proxy optimizations): 14277 ± 159 ms
- Node v9.0.0-v8-canary-20170924 (with only half of the traps ported): 11789 ± 308 ms
- Gain in speed around 2.4 seconds which is ~17% better
Note: These results were provided by Timothy Gu. Thanks!
Chai.js is a popular assertion library which makes heavy use of proxies. We've created a kind of real-world benchmark by running its tests with different versions of V8 an improvement of roughly 1s out of more than 4s, average of 100 runs:
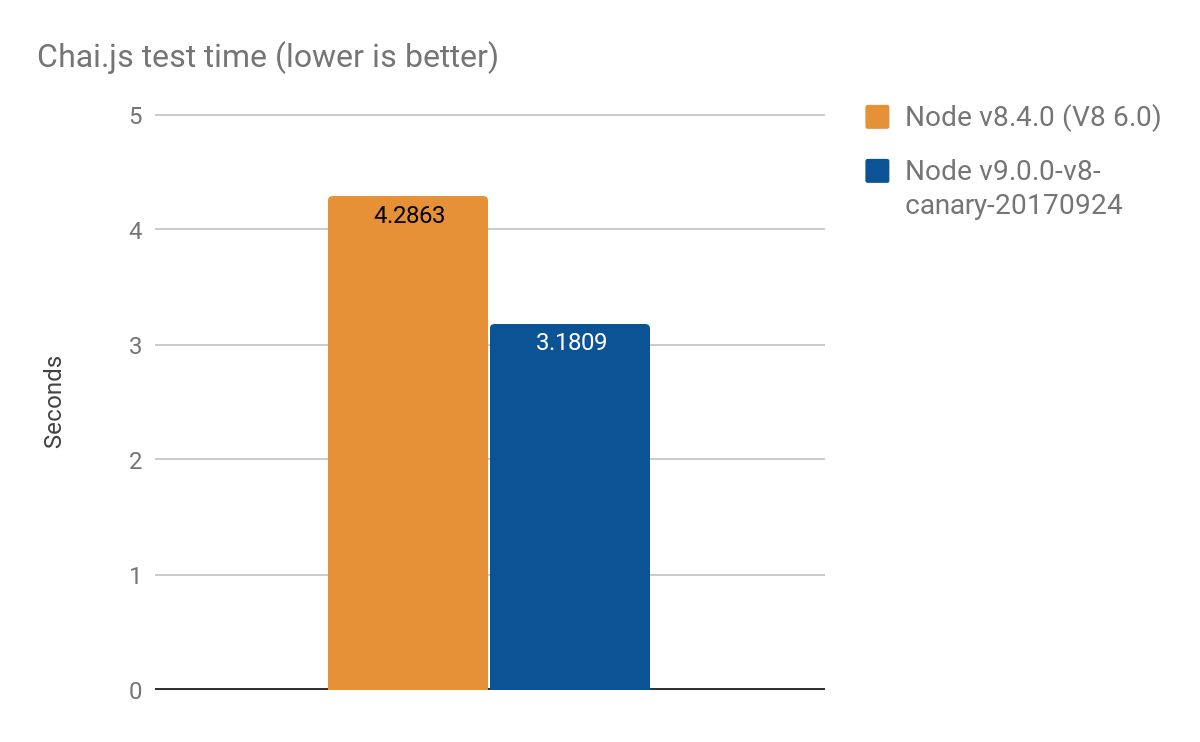
Optimization approach #
We often tackle performance issues using a generic optimization scheme. The main approach that we followed for this particular work included the following steps:
- Implement performance tests for the particular sub-feature
- Add more specification conformance tests (or write them from scratch)
- Investigate the original C++ implementation
- Port the sub-feature to the platform-agnostic CodeStubAssembler
- Optimize the code even further by hand-crafting a TurboFan implementation
- Measure the performance improvement.
This approach can be applied to any general optimization task that you may have.