V8 中的 JavaScript 对象在 V8 的垃圾回收器管理的堆上分配。在之前的博文中,我们已经讨论了如何减少垃圾回收停顿时间(不止一次)和内存消耗。在这篇博文中,我们介绍了并行 Scavenger,这是 Orinoco 的最新特性之一,V8 的主要并发和并行垃圾回收器,并讨论了我们在此过程中实现的设计决策和替代方法。
V8 将其托管堆(managed heap)分成几代,其中对象最初在新生代(young generation)的“区域(nursery)”中分配。在垃圾回收中幸存下来后,对象被复制到中间代(intermediate generation),它仍然是新生代的一部分。在另一次垃圾回收中幸存下来后,这些对象被移动到老年代(old generation)(见图 1)。V8 实现了两种垃圾回收器:一种是频繁回收新生代,另一种是回收包括新生代和老年代在内的完整堆。从老年代到新生代的引用是新生代垃圾回收的根源。记录这些引用以在移动对象时提供有效的根标识和引用更新。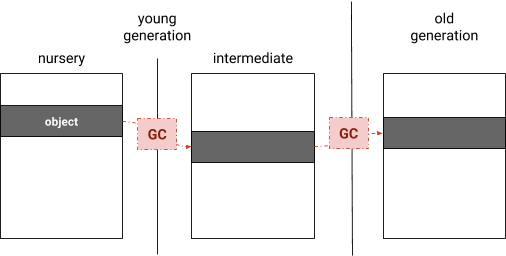 图 1:分代垃圾回收
图 1:分代垃圾回收
由于新生代相对较小(在 V8 中最高至 16MiB),它很快就会被对象填满并且需要频繁的回收。在 M62 之前,V8 使用 Cheney 半空间复制垃圾回收器(见下文)将新生代分成两半。在 JavaScript 执行期间,只有一半的新生代可用于分配对象,而另一半则保持为空。在新生代垃圾回收期间,活动对象(live objects)从一半复制到另一半,进行动态压缩内存。已经被复制一次的存活对象被认为是中间代的一部分,并被提升(晋升)到老年代。
从 v6.2 开始,V8 将回收新生代的默认算法切换为并行 Scavenger,类似于 Halstead 的半空间复制回收器,不同之处在于 V8 使用动态而不是跨多个线程的静态工作窃取(work stealing)。下面我们将解释三种算法:a) 单线程 Cheney 半空间复制收集器,b) 并行 Mark-Evacuate 方案,以及 c) 并行 Scavenger。
单线程 Cheney’s 半空间复制 #
在 v6.2 之前,V8 使用 Cheney 的半空间复制算法,该算法非常适合单核执行和分代方案。在新生代回收之前,内存的两个半空间都被提交并分配了适当的标签:包含当前对象集的页面称为 from-space,而将对象复制到的页面称为 to-space。
Scavenger 将调用堆栈中的引用以及从老年代到新生代的引用视为根。图 2 说明了算法,Scavenger 首先扫描从这些根可访问到的在 from-space 中的对象,并将还未复制到 to-space 中的对象复制过去。已经在垃圾回收中幸存下来的对象被提升(移动)到老年代。在根扫描和第一轮复制之后,对新分配的 to-space 中的对象进行引用扫描。类似地,所有晋升的对象都会被扫描以寻找对 from-space 的新引用。这三个阶段在主线程上交错进行。该算法一直持续到无法从 to-space 或老年代访问更多新对象。此时 from-space 只包含无法访问的对象,即它只包含垃圾。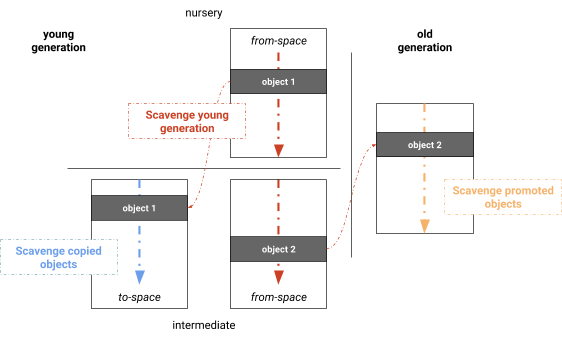 图 2:V8 中用于新生代垃圾回收的 Cheney 半空间复制算法
图 2:V8 中用于新生代垃圾回收的 Cheney 半空间复制算法 流程
流程
并行 Mark-Evacuate #
我们尝试了基于 V8 的完整 Mark-Sweep-Compact(标记-清除-压缩) 回收器的并行 Mark-Evacuate 算法。主要优势是利用来自完整 Mark-Sweep-Compact 回收器的现有垃圾回收基础设施。该算法由标记(marking)、复制(copying)和更新指针(updating pointers)三个阶段组成,如图 3 所示。为了避免在新生代中清扫页面来维护空闲列表,新生代仍然使用一个半空间来维护,通过在垃圾回收期间将活动对象复制到 to-space 中始终保持紧凑。新生代最初是并行标记的。标记后,活动对象被并行复制到其相应的空间。工作是基于逻辑页面分布的。参与复制的线程保留自己的本地分配缓冲区 (LABs),它们在完成复制后合并。复制后,应用相同的并行化方案来更新对象间指针。这三个阶段是以固定步骤(lockstep)执行的,即,虽然这些阶段本身是并行执行的,但线程在继续下一个阶段之前必须同步。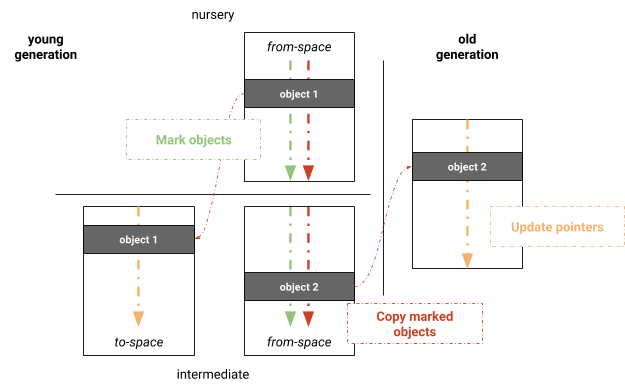 图 3:V8 中的新生代并行 Mark-Evacuate 垃圾回收
图 3:V8 中的新生代并行 Mark-Evacuate 垃圾回收 流程
流程
并行 Scavenge #
并行的 Mark-Evacuate 回收器将计算活跃度(computing liveness)、复制活跃对象(copying live objects)和更新指针(updating pointers)的阶段分开。一个明显的优化是合并这些阶段,从而产生同时标记、复制和更新指针的算法。通过合并这些阶段,我们实际上得到了 V8 使用的并行 Scavenger,该版本类似于 Halstead 的半空间回收器,不同之处在于 V8 使用动态工作窃取(work stealing)和简单的负载均衡机制来扫描根(见图 4)。和单线程 Cheney 算法一样,阶段是:扫描根(scanning for roots),新生代内复制(copying within the young generation),晋升到老年代(promoting to the old generation),更新指针(updating pointers)。我们发现大部分根集通常是从老年代到新生代的引用。在我们的实现中,记忆集(remembered sets)是按页维护的,这自然地在垃圾回收线程之间分配根集。然后并行处理对象。新发现的对象被添加到垃圾收集线程可以窃取(steal)的全局工作列表中。此工作列表提供快速任务本地存储以及共享工作的全局存储。当当前处理的子图不适合工作窃取(例如对象的线性链)时,屏障确保任务不会过早终止。所有阶段在每个任务上并行执行和交错执行,最大限度地提高工作任务的利用率。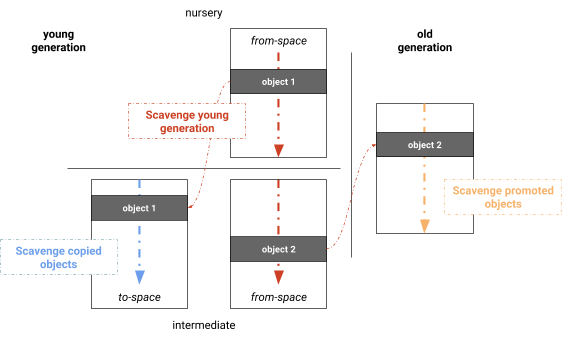 图 4:V8 中的新生代并行 Scavenger
图 4:V8 中的新生代并行 Scavenger 流程
流程
结果和产出 #
Scavenger 算法最初的设计考虑到了最佳的单核性能。从那时起,世界发生了变化。CPU 内核资源通常很丰富,即使在低端移动设备上也是如此。更重要的是,通常这些核心实际上已启动并运行。为了充分利用这些核心,V8 垃圾回收器的最后一个顺序组件之一 Scavenger 必须进行现代化改造。
并行 Mark-Evacuate 回收器的一大优势是可以获得准确的活跃信息( liveness information)。该信息是有用的,例如通过移动和重新链接包含大部分活动对象的页面来避免复制,这也由完整的 Mark-Sweep-Compact 回收器执行。然而,在实践中,这主要是在综合基准测试中观察到的,很少出现在真实网站上。并行 Mark-Evacuate 回收器的缺点是执行三个单独的固定步骤阶段的开销。当垃圾回收器在堆上调用的大部分是死对象时,这种开销尤其明显,许多现实世界的网页都是这种情况。请注意,在大部分为死对象的堆上调用垃圾回收实际上是理想的情况,因为垃圾回收通常受活动对象的大小限制。
并行 Scavenger 通过在小堆或几乎为空的堆上提供接近优化的 Cheney 算法的性能来缩小这一性能差距,同时在堆因大量活动对象而变大的情况下仍提供高吞吐量。
V8 支持许多其它平台,如 Arm big.LITTLE。虽然卸载小内核上的工作有利于电池寿命,但当小内核的工作包太大时,它可能导致主线程停顿。我们观察到,由于页面数量有限,页面级并行性不一定会在 big.LITTLE 上为新生代垃圾回收进行负载均衡工作。Scavenger 通过使用显式工作列表和工作窃取(work stealing)提供中等粒度的同步自然地解决了这个问题。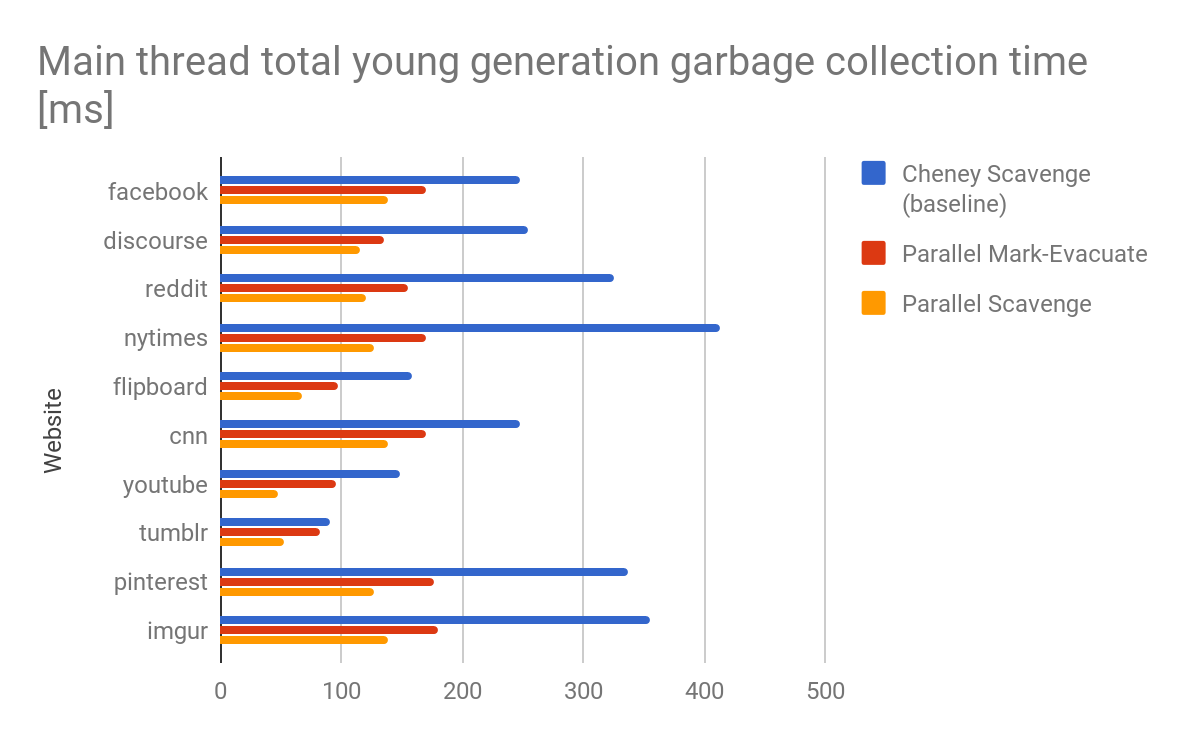 图 5:各个网站的新生代垃圾回收总时间(以毫秒为单位)
图 5:各个网站的新生代垃圾回收总时间(以毫秒为单位)
V8 现在附带了并行 Scavenger,它在大量基准测试中将主线程新生代垃圾回收的总时间减少了大约 20%–50%(我们的性能瀑布的详细信息)。图 5 显示了各种真实世界网站的实现比较,显示了大约**55%(2 倍)**的改进。在保持最小停顿时间的同时,可以在最大和平均停顿时间上观察到类似的改进。并行的 Mark-Evacuate 回收器方案仍有优化的潜力。如果你想知道接下来会发生什么,请继续关注。